Basic Information
MM-quecat is a member of the multi-model data modeling and management tool family. Namely, the tool enables one to query multi-model data regardless of the underlying multi-model database or polystore.
Using category theory, we provide a unified abstract representation of multi-model data, which can be viewed as a graph and, thus, queried using a SPARQL-based query language.
Authors:
- Irena Holubová
- Pavel Koupil
- Daniel Crha
Demonstration
For the purpose of demonstration of key contributions, MM-quecat supports unified querying over four database systems chosen to cover most of the features of different approaches to querying (multi-model) data. In particular:
- PostgreSQL is a representative of a large family of systems which employ the SQL language to query over flat data.
- MongoDB and Apache Cassandra are representatives of systems that support querying over hierarchical data.
- Neo4j serves as a representative of systems that allow querying over graphs, e.g., graph traversal and graph pattern matching.
We expect that the user has already created a categorical schema for the multi-model data, either manually using the MM-evocat or by extracting the schema from the data using the MM-infer. Hence, in the demo of MM-quecat, we utilize the existing categorical schema and we gradually go through the process of querying of multi-model data utilizing proposed multi-model query language MMQL and we demonstrate all interesting cases.
Demonstration Outline
In particular, the following steps will be taken during the demonstration:
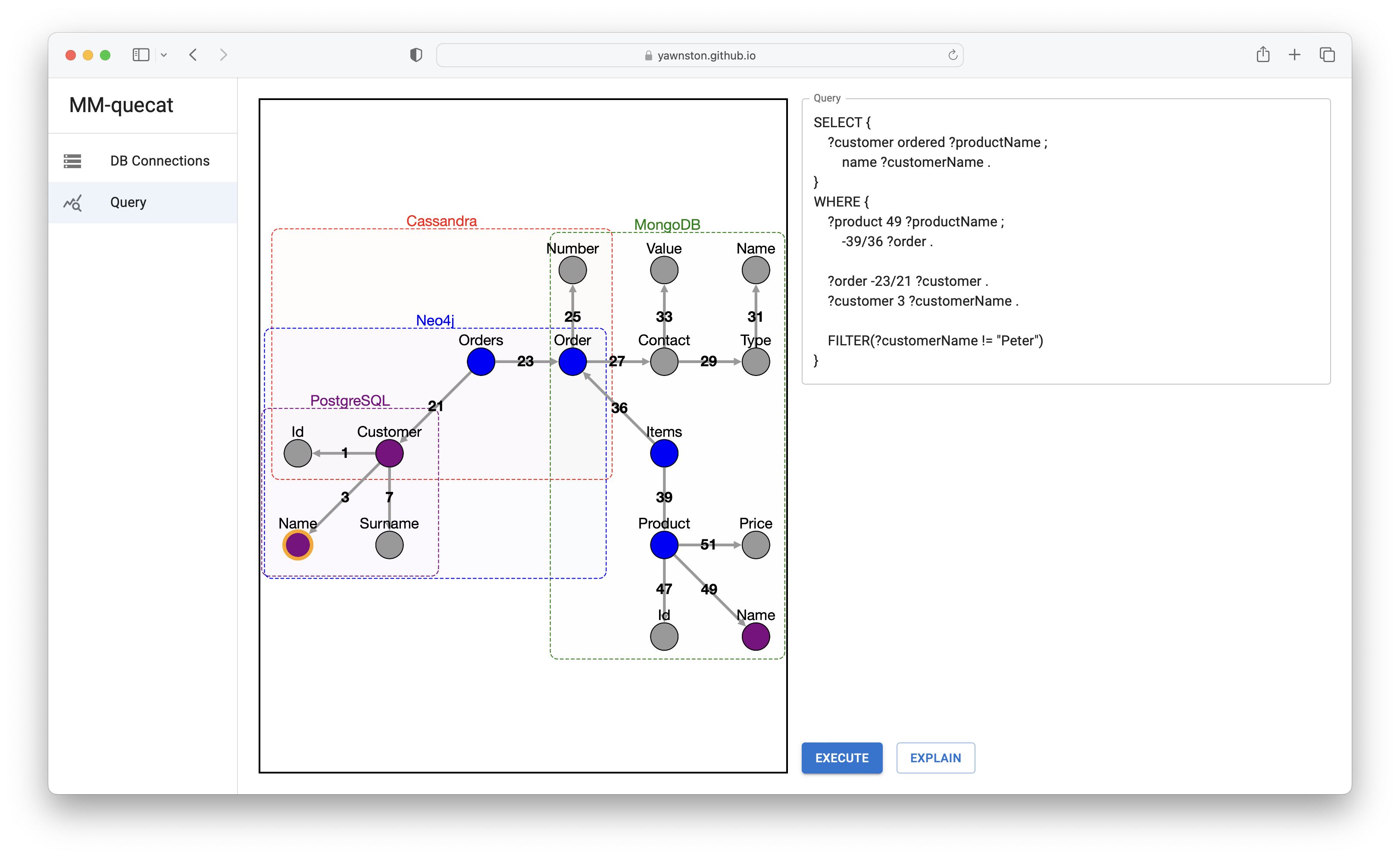
- The first step is to create a query over the multi-model data. The user queries over the data structure, which we describe using a categorical schema. A skilled user can enter the query using the MMQL text notation. Alternatively, we also introduce a graphical notation of the query language for less technically skilled users, who can access the data using a manual graph exploration.
- Subsequently, each query is decomposed according to the mapping of the schema to the underlying database systems. It may happen that a user has multiple strategies to choose from to execute a query, e.g., when the same data are redundantly stored in multiple underlying systems. Moreover, all query evaluation strategies are price tagged (i.e., a plan cost for each strategy exists).
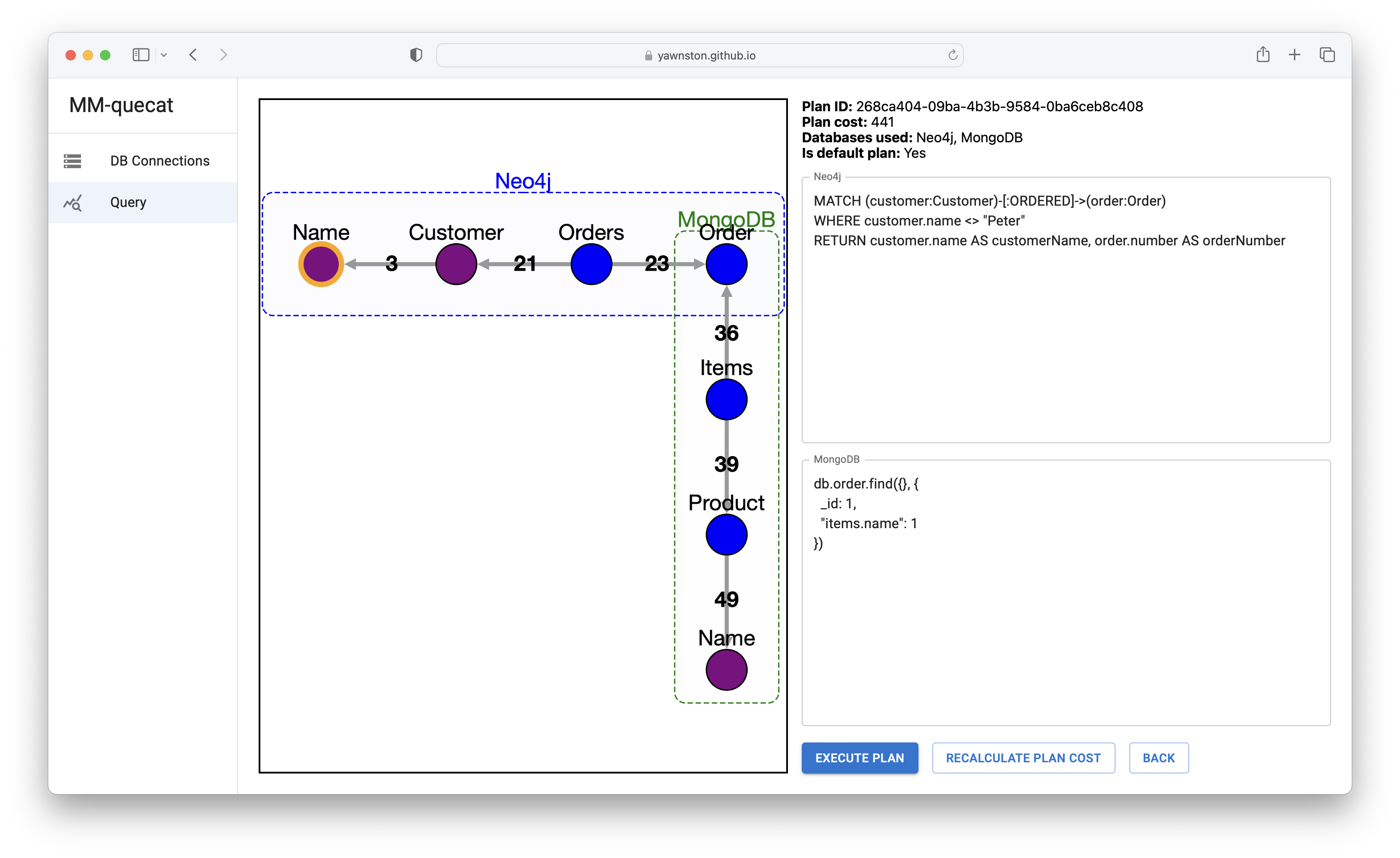
- In this particular case, the cost-effective strategy is to decompose the query into two query parts, namely over Neo4j and MongoDB systems. The former performs the projection of customer names and identifiers of the orders they have ordered, except for customers named "Peter". The latter returns all titles ordered in a particular order.
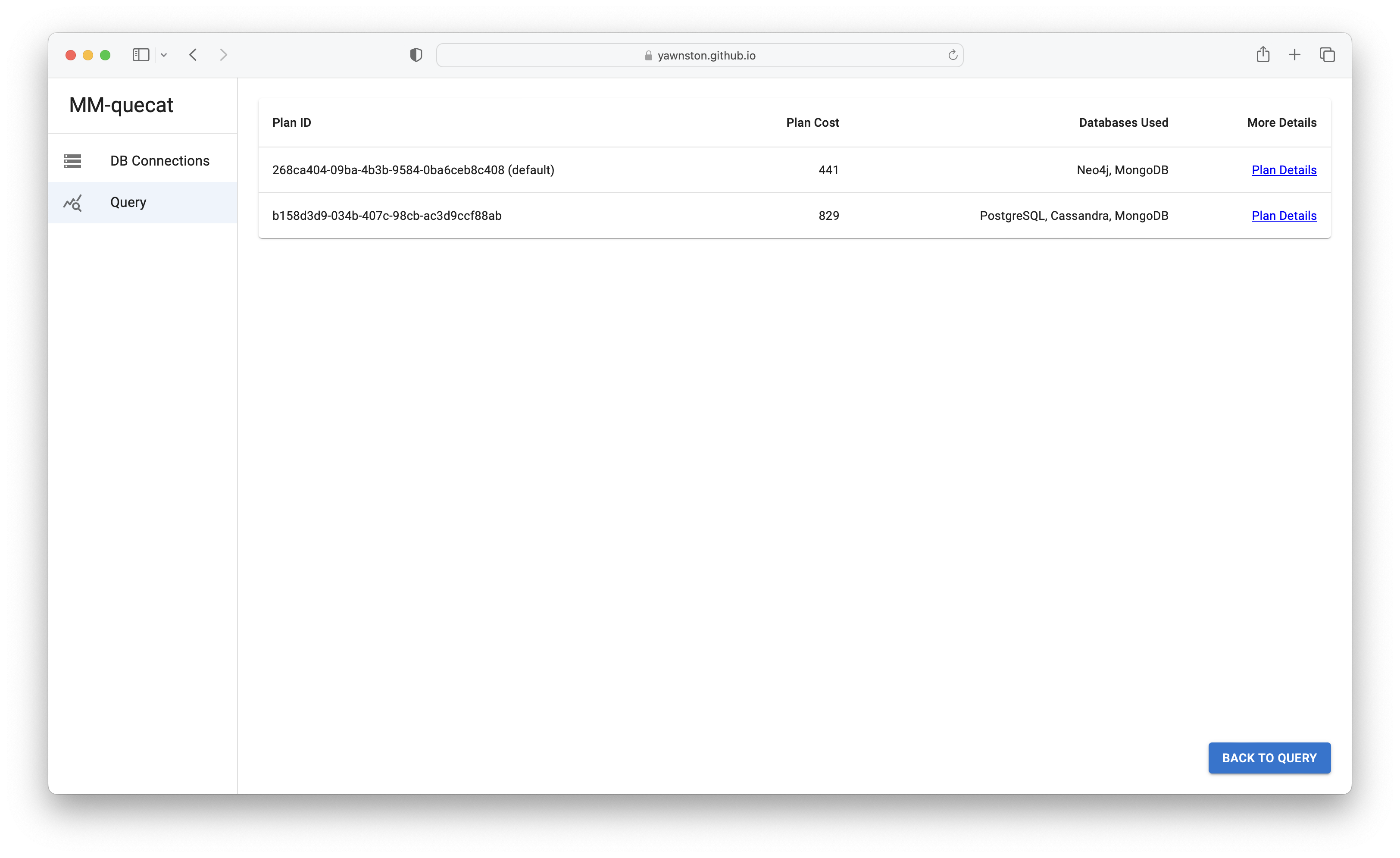
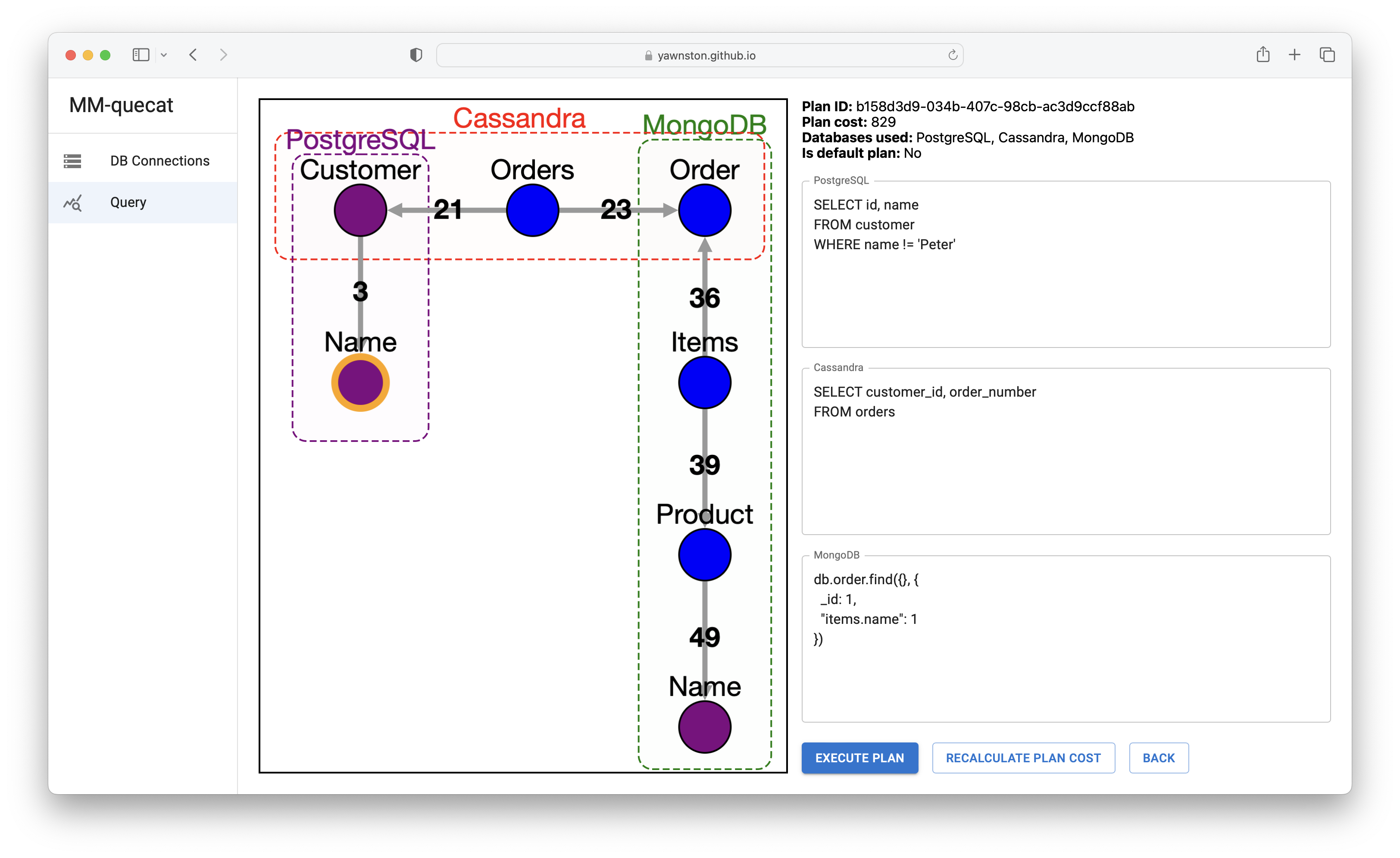
- The alternative plan is to decompose the query into three query parts over PostgreSQL, Apache Cassandra and MongoDB. Customer names except for name "Peter" along with their identifier are retrieved from PostgreSQL, ordered products along with the order identifier are retrieved from MongoDB, and the connection of customers to ordered products is realized using the Customer-Orders-Order relationship stored in Apache Cassandra. Note that this plan is more expensive and hence is not marked as the default plan.
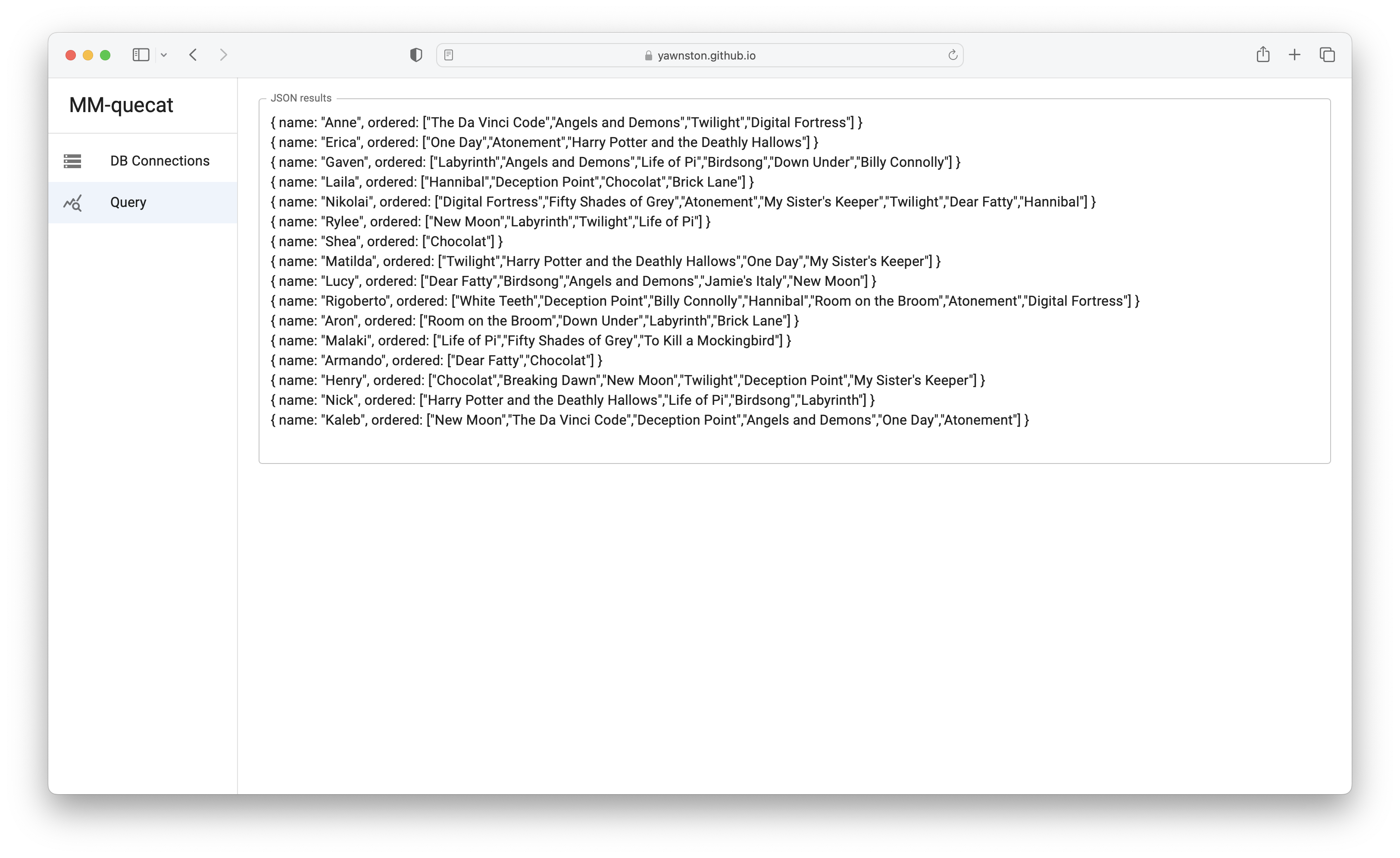
- Intermediate results are joined in a unified categorical representation and the query evaluation is finalized. Afterwards, the user can select the desired logical representation of the result, or the result can be returned in a unified representation. Currently, we support mapping the query result to JSON, RDF formats.
- In this case, the query result is transformed into JSON format, and the structure of the JSON document matches the structure of the result in the SELECT clause of the MMQL expression. However, we are working on an extension that would allow the user to create a mapping of the query result to more than one logical representation.
Publications
- Pavel Koupil, Sebastián Hricko, and Irena Holubová. A Universal Approach for Multi-Model Schema Inference. J Big Data 9, 97 (2022). Springer Nature. [Q1, 2Y-IF: 10.835, CiteScore: 14.57, SJR: 2.592] 10.1186/s40537-022-00645-9
- Pavel Koupil, and Irena Holubová. A unified representation and transformation of multi‐model data using category theory. J Big Data 9, 61 (2022). Springer Nature. [Q1, 2Y-IF: 10.835, CiteScore: 14.57, SJR: 2.592] 10.1186/s40537-022-00613-3
- Pavel Koupil, Jáchym Bártík, and Irena Holubová. MM-evocat: A Tool for Modelling and Evolution Management of Multi-Model Data. 31st ACM International Conference on Information and Knowledge Management, CIKM 2022. Atlanta, Georgia, USA, October 2022. [CORE A] 10.1145/3511808.3557180
- Pavel Koupil, Sebastián Hricko, and Irena Holubová. Schema Inference for Multi-Model Data. 25th International Conference on Model Driven Engineering Languages and Systems, MODELS 2022. Montreal, Canada, October 2022. [CORE A] 10.1145/3550355.3552400
- Pavel Koupil, Sebastián Hricko, and Irena Holubová. MM-infer: A Tool for Inference of Multi-Model Schemas. 29th International Conference on Extending Database Technology, EDBT 2022. Edinburgh, UK, March 2022. [CORE A] 10.48786/edbt.2022.52 [presentation]
- Pavel Koupil, Martin Svoboda, and Irena Holubová. MM-cat: A Tool for Modeling and Transformation of Multi-Model Data using Category Theory. 24th International Conference on Model Driven Engineering Languages and Systems, MODELS 2021. Fukuoka, Japan, October 2021. [CORE A] 10.1109/MODELS-C53483.2021.00098 [presentation]