Basic Information
A modular and extensible framework that ensures inference of a common schema of multi-model data. It enables to re-use verified single-model approaches, it is able to reveal both intra- and inter-model references as well as overlapping of models, i.e., data redundancy. Following the current trends, the implementation can process efficiently also large amounts of data.
Authors:
- Irena Holubová
- Pavel Koupil
- Sebastián Hricko
Demonstration
For the purpose of demonstration of key contributions, MM-infer supports three DBMSs selected in order to cover most of the distinct features related to schema inference. In particular:
- PostgreSQL can serve as a schema-full single-model (relational) and schema-mixed multi-model (relational, JSON and XML document) DBMS.
- Neo4j represents the schema-less graph DBMS.
- MongoDB represents both schema-full and schema-less document DBMS.
If there is more than one possibility how to treat a DBMS, for each of the options there are implemented respective separate wrappers.
In our demo of MM-infer, we will gradually go through the process of schema inference of a part of the multi-model scenario from Unibench extended to demonstrate all interesting cases.
Demonstration Outline
In particular, the following steps will be taken during the demonstration:
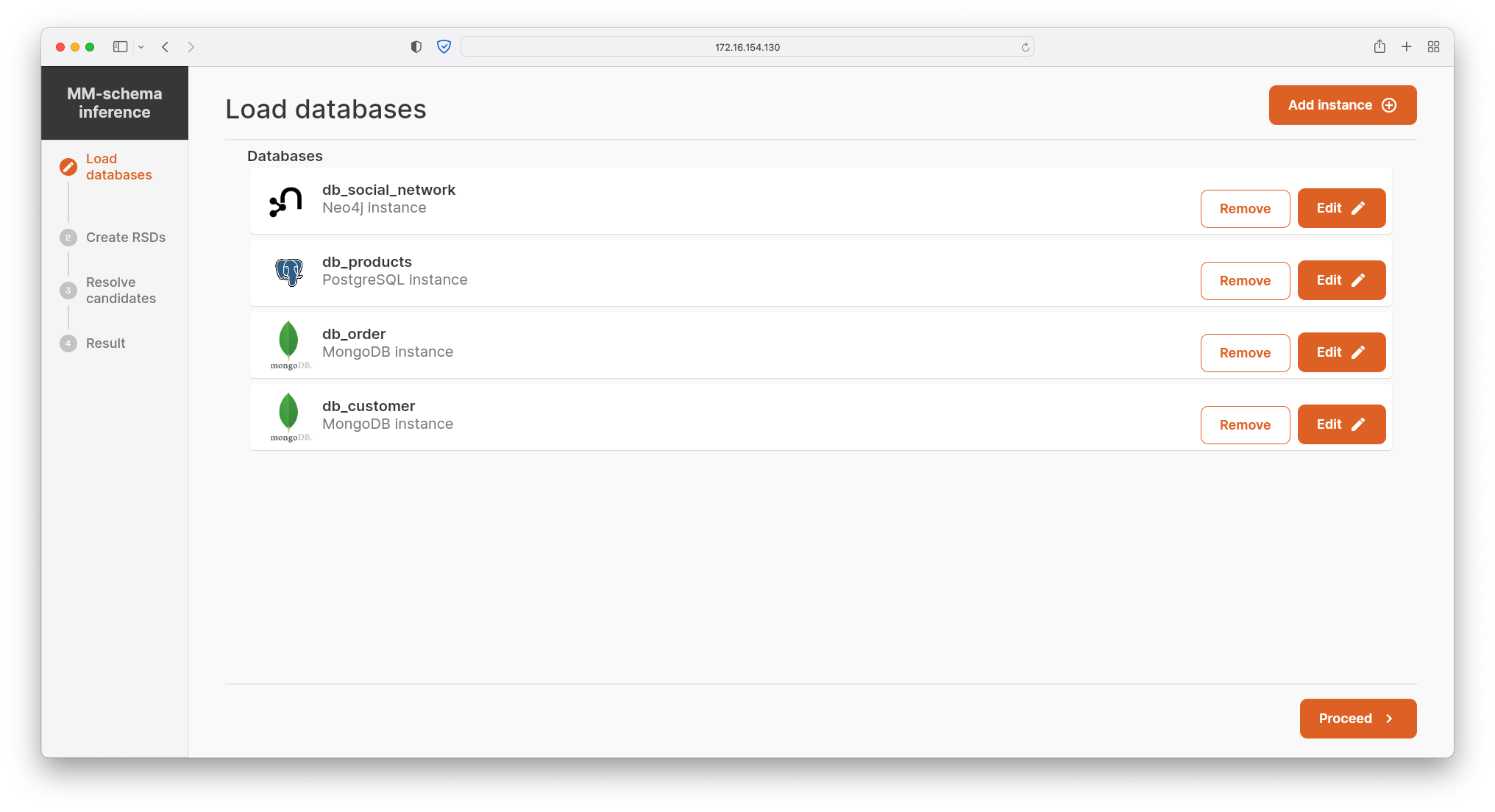
- The user selects a set of named single- or multi-model DBMSs, i.e., creates a polystore, that will be used in the process of the schema inference. Once added, the particular DBMS instance can be edited or removed.
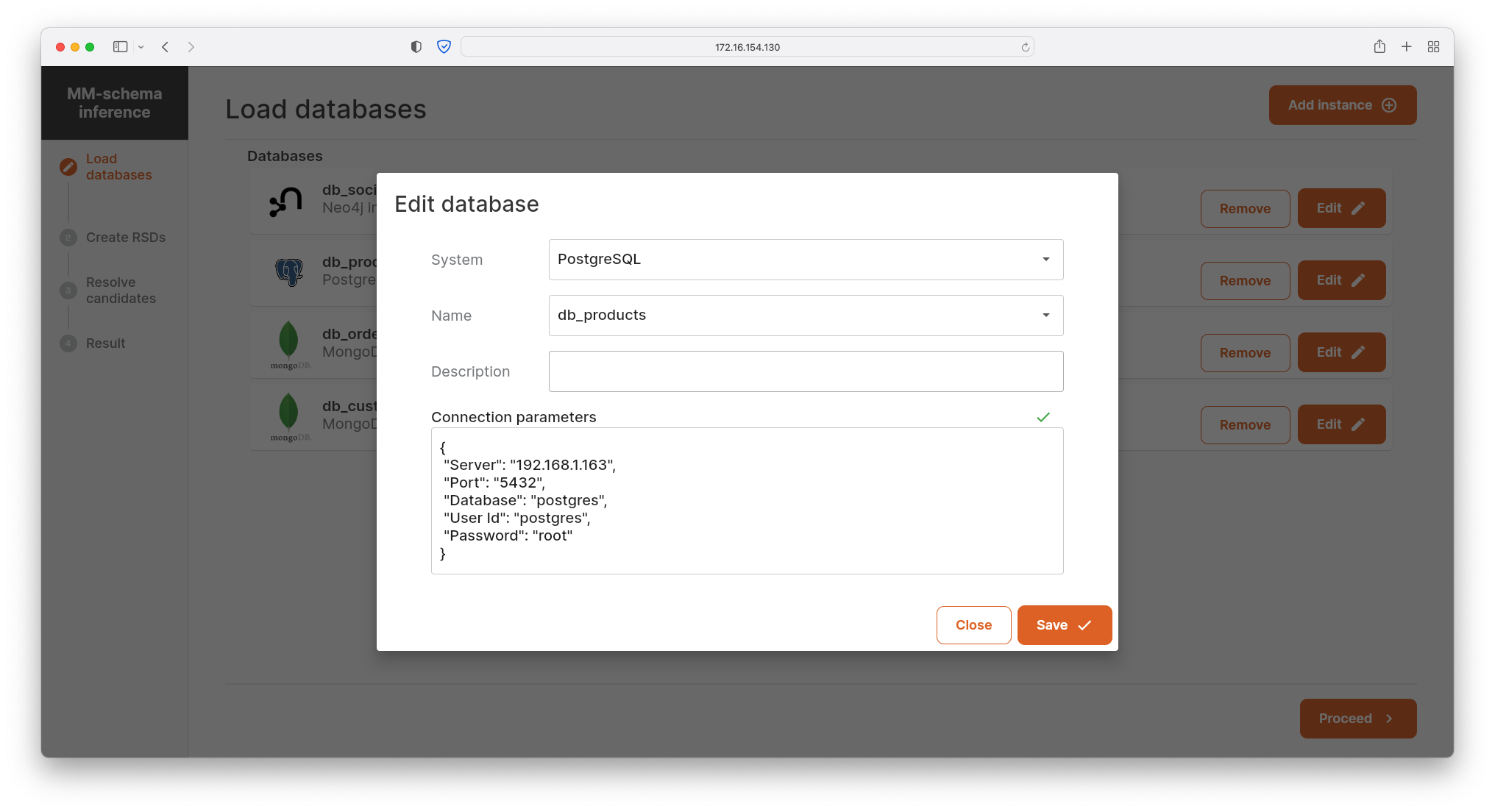
- The user can choose from a range of supported DBMSs, select a particular database instance, and set its optional description. Finally, based on a particular DBMS wrapper, the user also specifies the connection to the database, e.g., hostname, port, database, user, and password.
- The set of the DBMSs is automatically loaded and kinds stored in the respective database instances are trivially compared, which results in the redundancy recommendations (i.e., overlapping data). The user confirms/refutes these candidates.
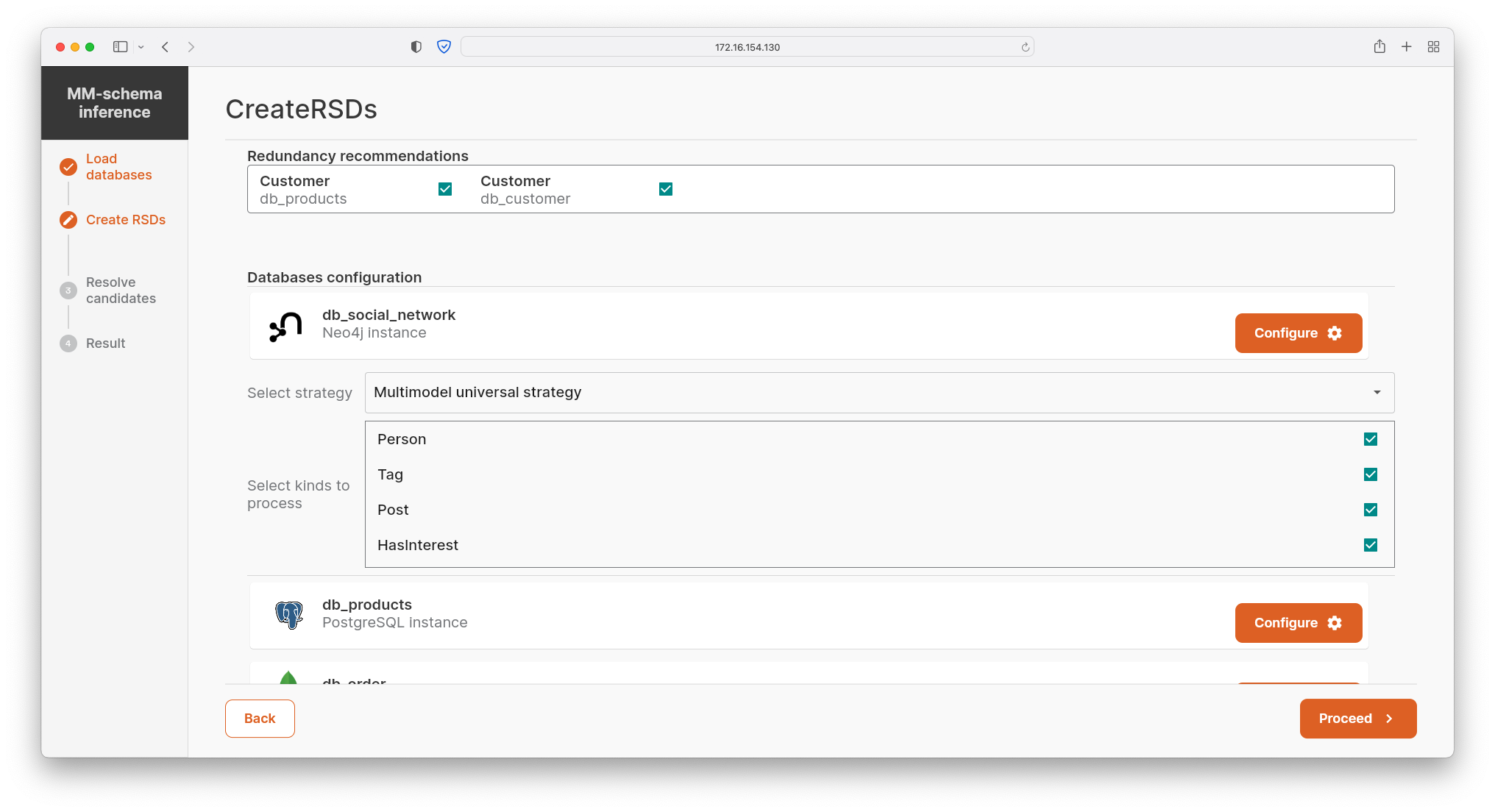
- The user selects kinds in the chosen DBMSs to be used for inference of RSDs and selects the respective inference strategy: 1) inherit, i.e., loading of an existing schema from schema-full data, 2) verified existing strategy for a particular schema-less data (e.g., JSON, XML), or 3) universal strategy covering schema-mixed and schema-less multi-model data in general.
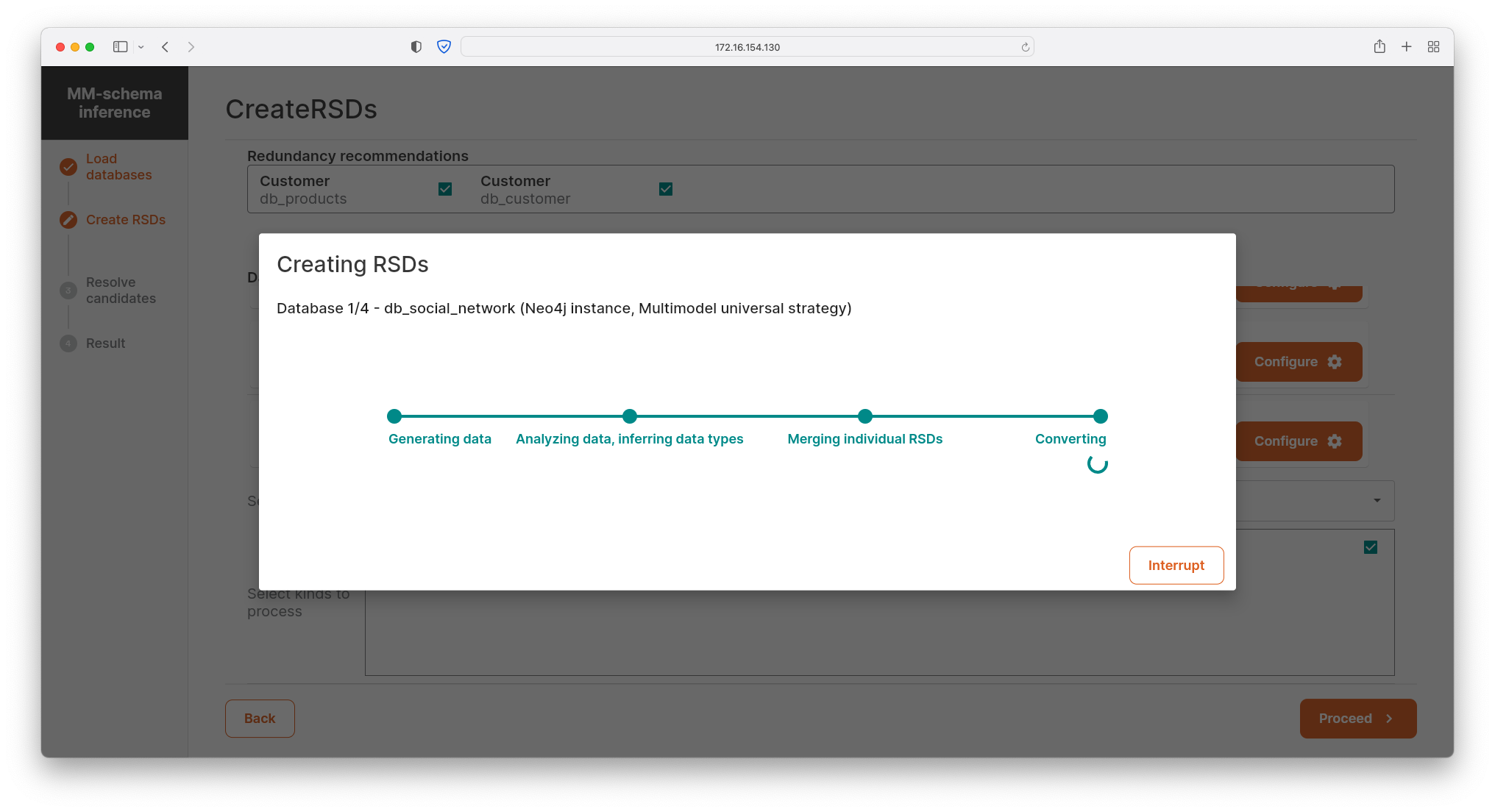
- Having defined database instances and particular kinds to be inferred, the distributed Apache Spark task processes all the data (or theirs schemas, if exist) on background and creates local schemas for each kind. In parallel, the additional task is executed in order to generate candidates for redundancy, references and selected integrity constraints.
- The user modifies suggested candidates for basic integrity constraints. In the current version of MM-infer, the user confirms/refutes candidates for intra- and inner-model references, inferred data types of particular properties, and a range of values for each property.
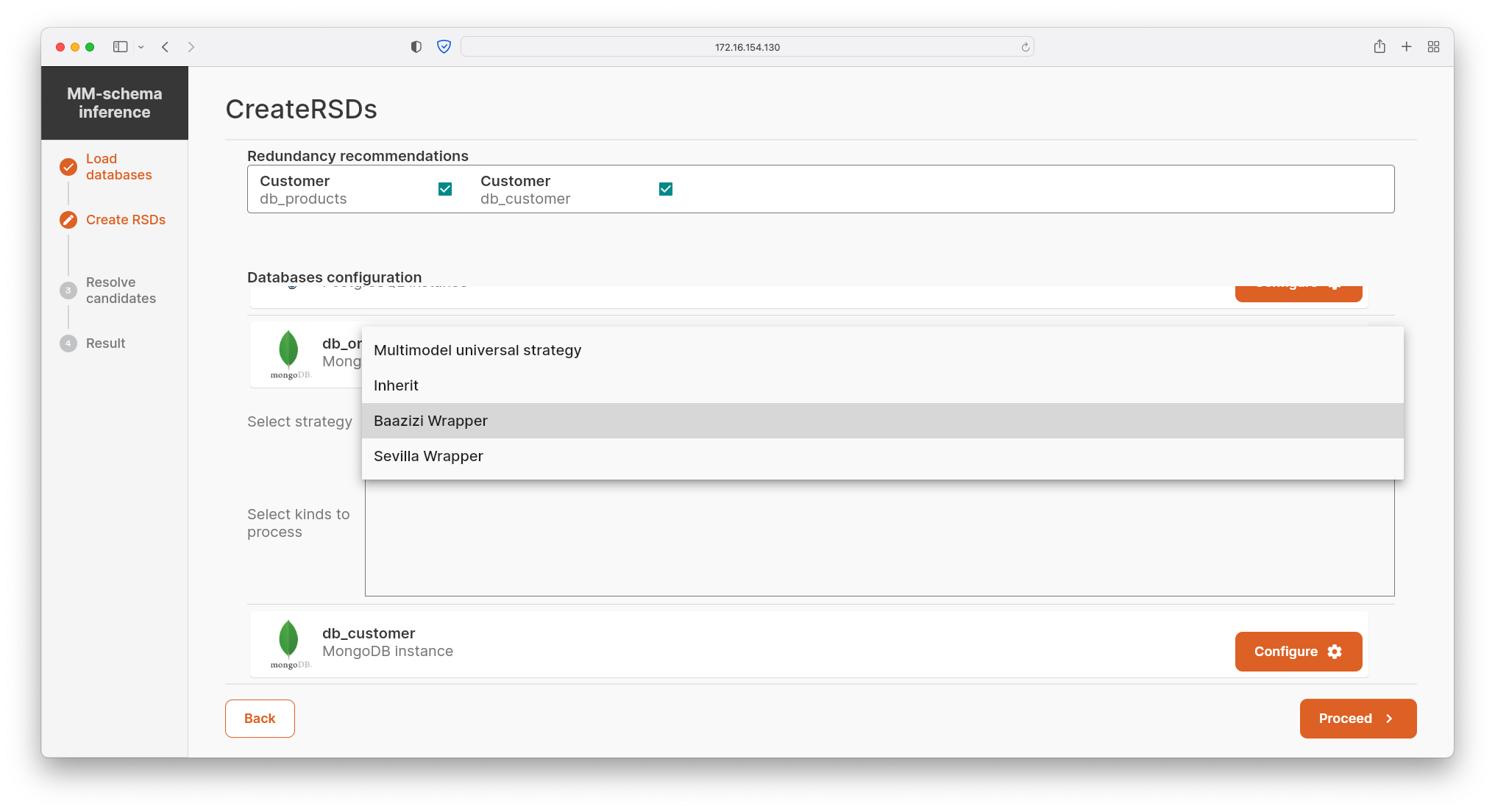
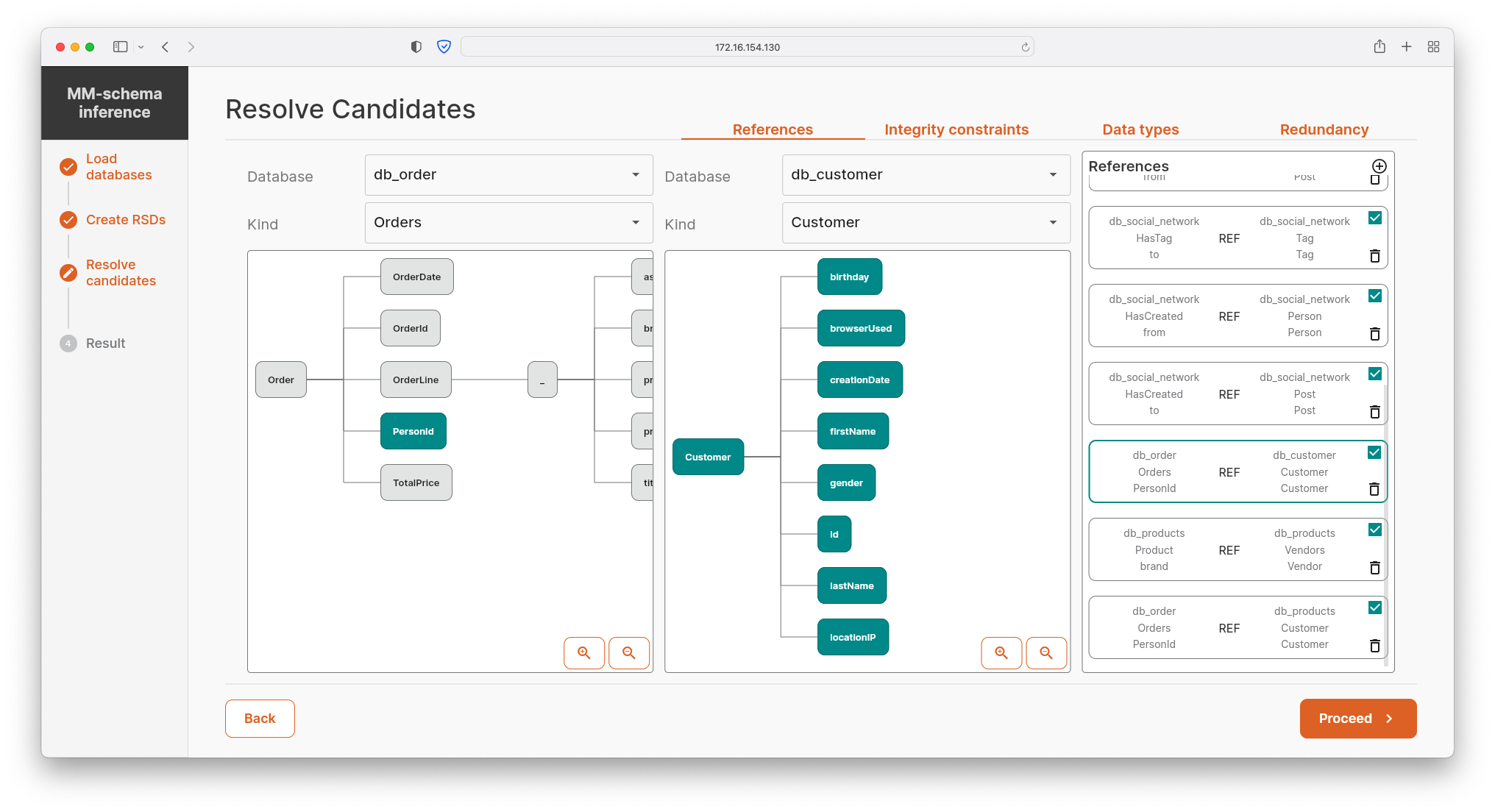
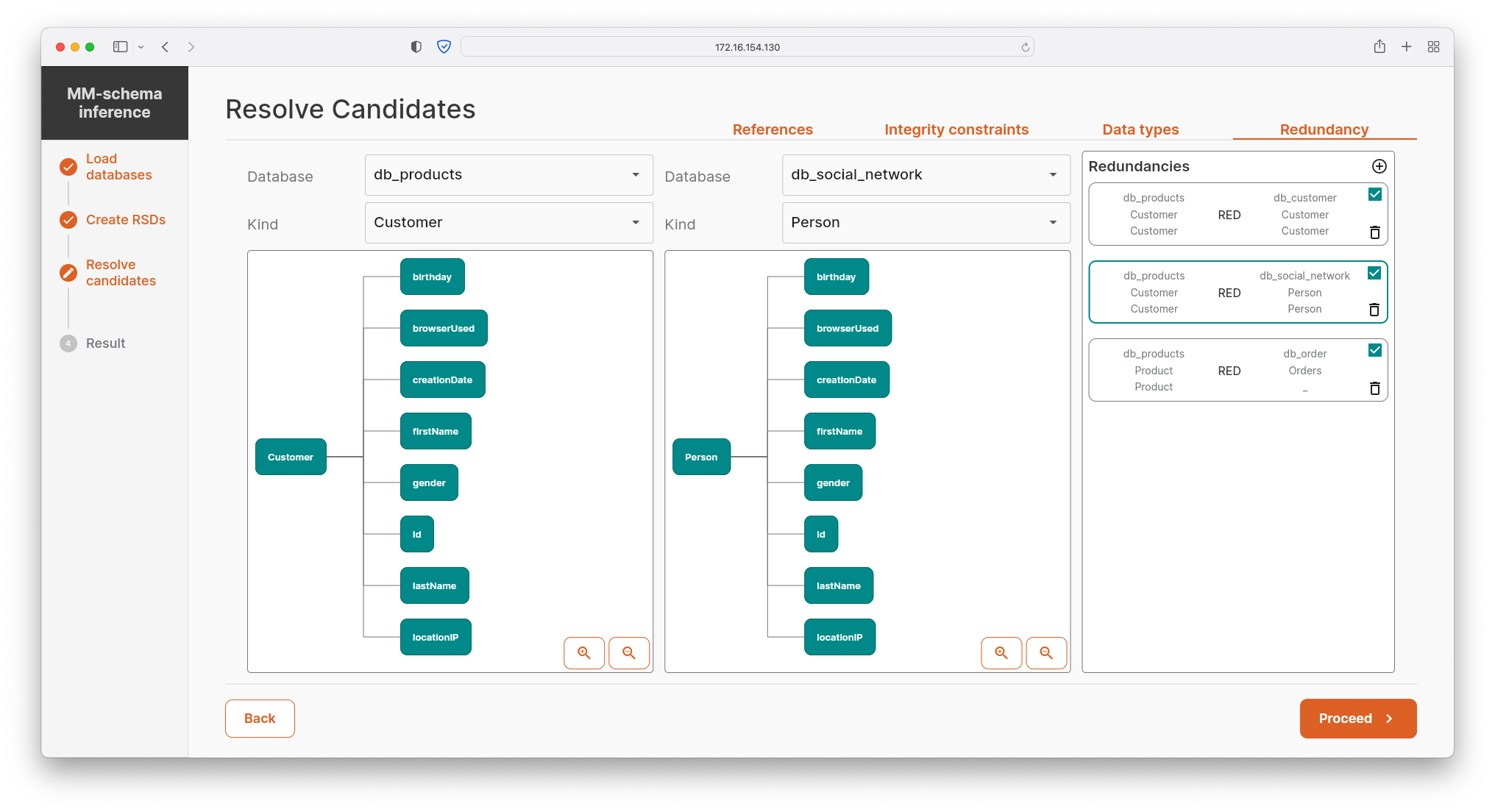
- In addition, the user confirms/refutes pre-computed candidates for data redundancy. The redundancy may be of two types: 1) a complete data overflow in which the active domains of two particular kinds are equal, or 2) a partial data redundancy, where data of one kind are a subset of data of another kind, e.g., Customer being a subset of Person.
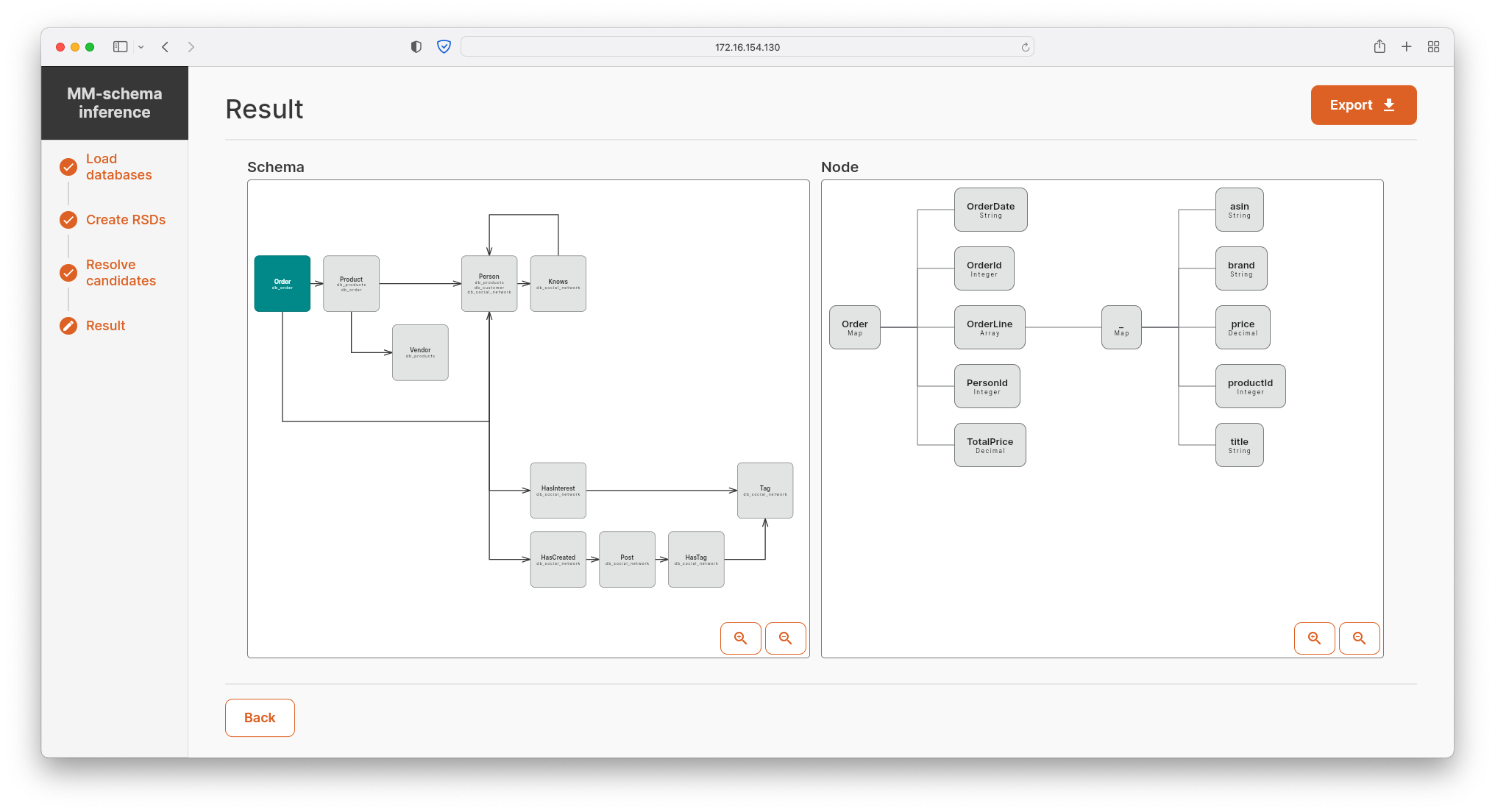
- Having merged all the local schemas and checked candidates for integrity constraints and data redundancy, MM-infer visualizes global schema of the chosen set of DBMSs (including references and data redundancy). Additionally, the resulting RSD can be exported into various popular formats, e.g., JSON Schema, XML Schema, etc.
Publications
- Klempa, M. - Kozak, M. - Mikula, M. - Smetana, R. - Starka, J. - Svirec, M. - Vitasek, M. - Necasky, M. - Holubova (Mlynkova), I.: jInfer: A Framework for XML Schema Inference. The Computer Journal, volume 11, issue 2, pages 134 - 156. Oxford University Press, 2015. ISSN 0010-4620.
- Mlynkova, I. - Necasky, M.: Heuristic Methods for Inference of XML Schemas: Lessons Learned and Open Issues. Informatica, volume 24, issue 4, pages 577 - 602. IOS Press, 2013. ISSN 0868-4952.
- Vitasek, M. - Mlynkova, I.: Inference of XML Integrity Constraints. ADBIS '12: Proceedings of the 16th East-European Conference on Advances in Databases and Information Systems, pages 285 - 296, Poznan, Poland, September 2012. Advances in Intelligent and Soft Computing, Springer-Verlag, 2012. ISBN 978-3-642-32740-7. ISSN 2194-5357.
- Kozak, M. - Starka, J. - Mlynkova, I.: Schematron Schema Inference. IDEAS '12: Proceedings of the 16th International Database Engineering & Applications Symposium, pages 42 - 50, Prague, Czech Republic, August 2012. ACM Press, 2012. ISBN 978-1-4503-1234-9.
- Mlynkova, I. - Necasky, M.: Towards Inference of More Realistic XSDs. SAC '09: Proceedings of the 24th Annual ACM Symposium on Applied Computing - track Web Technologies, pages 632 - 638, Honolulu, Hawaii, USA, March 2009. ACM Press, 2009. ISBN: 978-1-60558-166-8. Note: The Best Paper Award
- Vosta, O. - Mlynkova, I. - Pokorny, J.: Even an Ant Can Create an XSD. DASFAA '08: Proceedings of the 13th International Conference on Database Systems for Advanced Applications, pages 35 - 50, New Delhi, India, March 2008. Lecture Notes in Computer Science 4947, Springer-Verlag, 2008. ISBN 978-3-540-78567-5. ISSN 0302-9743.
- Pavel Čontoš, and Martin Svoboda. 2020. JSON schema inference approaches. In International Conference on Conceptual Modeling (ER 2020). Lecture Notes in Computer Science, vol 12584. Springer, Cham, 2020. p. 173-183. ISBN 978-3-030-65846-5. DOI: 10.1007/978-3-030-65847-2_16