Basic Information
A modular and extensible framework that enables to design a multi-model schema. An initial ER schema is transformed to a unified categorical representation which can then be easily mapped to any combination of models in a particular DBMS, or their set.
In addition, MM-cat also provides a categorical representation of multi-model data instances to be processed uniformly. Both the schema and instance categories serve as the core for further management of multi-model data.
Authors:
- Irena Holubová
- Martin Svoboda
- Pavel Koupil
Demonstration
For the purpose of demonstration of key contributions, MM-cat supports two DBMSs selected in order to cover most of the distinct features related to data modeling. In particular:
- Schema-less (MongoDB) vs. schema-full/schema-mixed (PostgreSQL): We will demonstrate different approaches to the propagation of information about the specified structures to the particular DBMS. In both cases, the user specifies the required structures using MM-cat; however, only in the case of schema-full (or schema-mixed) DBMS is the information propagated to DDL commands. In addition, dynamically derived names of properties are also not allowed, e.g., in a schema-full relational DBMS.
Besides, MM-cat supports two cases of a schema-mixed approach:
- With a modeled schema: As mentioned above, the user specifies the schema, even if it is not fully propagated to the DBMS. This happens when the features of a particular multi-model DBMS (as we will see in PostgreSQL) do not support schema-on-write approach for some models (in PostgreSQL, it is represented by schema-less data type JSONB for JSON documents which can be used in a schema-full relational table). But the whole schema remains defined in the categorical representation and can be used, e.g., for external checking of data validity of the schema-less parts, conceptual cross-model querying, etc. (This approach can also be used for a schema-less DBMS, where we want to specify the schema externally.)
- Without a modeled schema: During the modeling phase, the user decides to leave a part of the schema unspecified, i.e., only a general data type (e.g., a BLOB) is assigned to a (part of a) kind. When the data stored in the DBMS is transformed to an instance category, the missing part of the schema can be inferred from the data instances. In other words, the schema-on-read approach is used for the purpose of further processing of the data now with a known structure.
- Aggregate-oriented (MongoDB) vs. aggregate-ignorant (PostgreSQL): We will demonstrate how the mapping process differs in the complexity of structures allowed by the particular type of a system, i.e., complex hierarchical structures allowing nesting and repetitions (arrays) vs. flat relations with only simple data types (or their combination in the case of multi-model PostgreSQL).
- Polystore vs. multi-model DBMS: We will show how MM-cat can handle modeling of a schema in the case of a polystore-like approach, i.e., combining models from several DBMSs, and in the case of a single multi-model DBMS which is capable of storing multiple models in a single system.
During the demonstration of MM-cat, we will gradually go through the process of modeling a part of the multi-model scenario introduced in Fig.~\ref{fig:example} and~\ref{fig:ERschema}. In addition, we will show how the categorical model enables user-friendly data migration without the need to deal with the technical specifics of particular systems. We will also indicate how advanced data management tasks (e.g., evolution management, cross-model querying, or multi-model schema inference) can be built on top of the categorical model.
Demonstration Outline
In particular, the following steps will be taken during the demonstration:
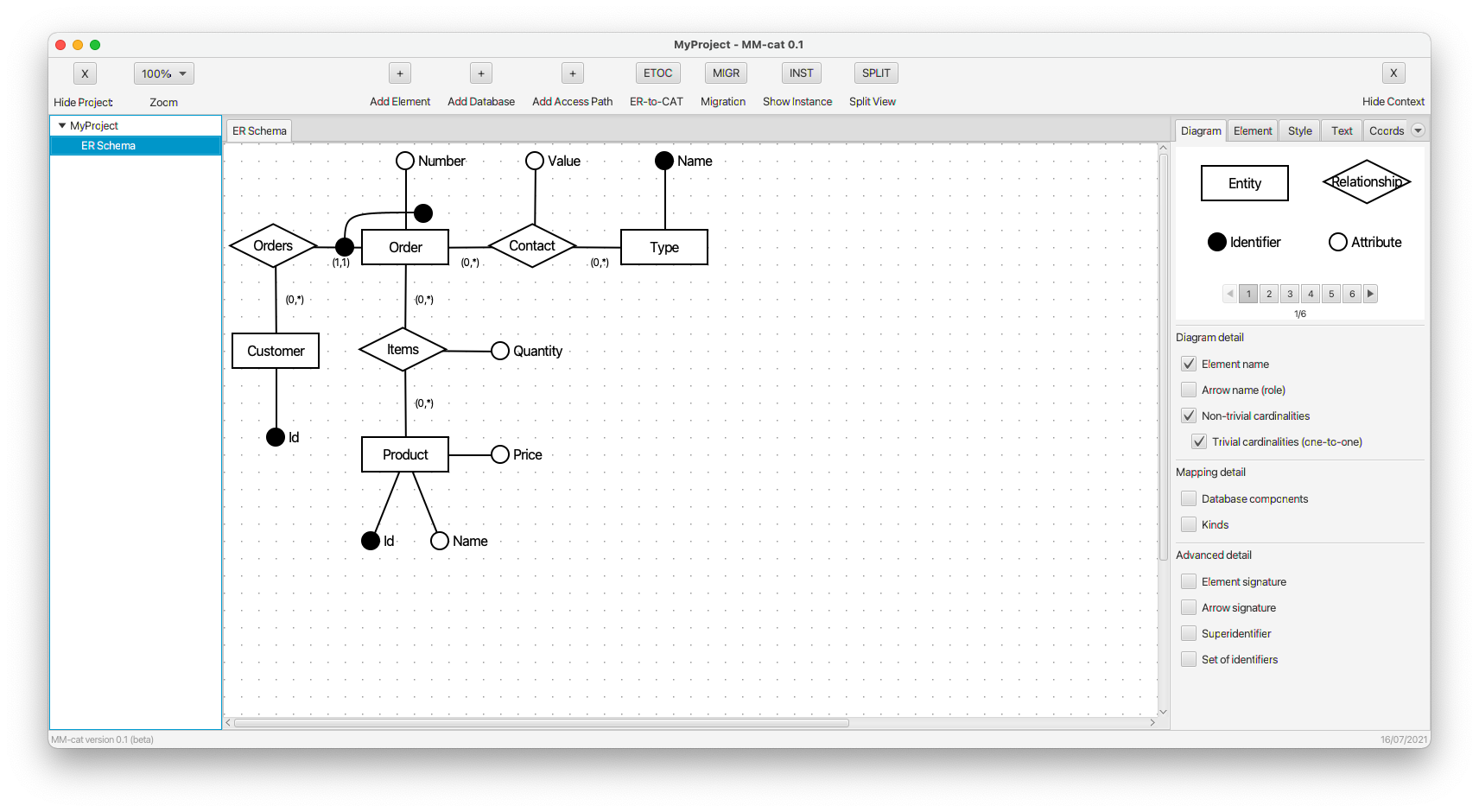
- The user creates an ER schema of the target domain of the application. For this purpose, MM-cat provides an editor of ER diagrams. The user can choose from a range of constructs, denote their features, and specify the required level of detail of visualization.
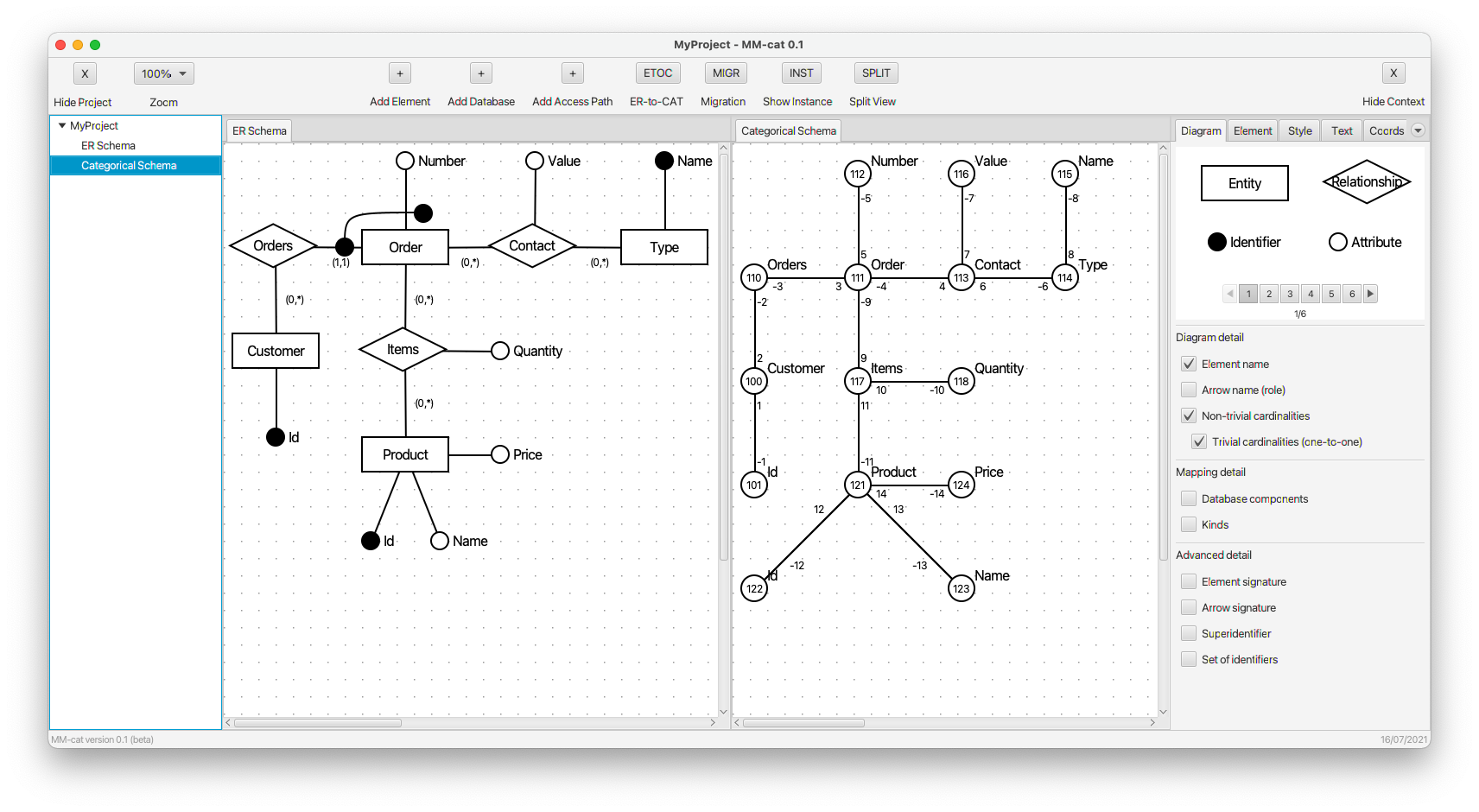
- The ER schema is automatically transformed to the respective schema category. However, the schema category can also be created directly from scratch. The auxiliary step via an ER diagram is added only for the purpose of easier understanding using a known modeling approach. Also, for the purpose of higher clarity, the layout of the graph of the schema category corresponds to the layout of the original ER diagram. Note that direct editing of the schema category is, at the same time, a preparation for evolution management, i.e., propagation of changes to all affected and already existing parts of the system (i.e., logical data structures, data instances, queries, etc.).
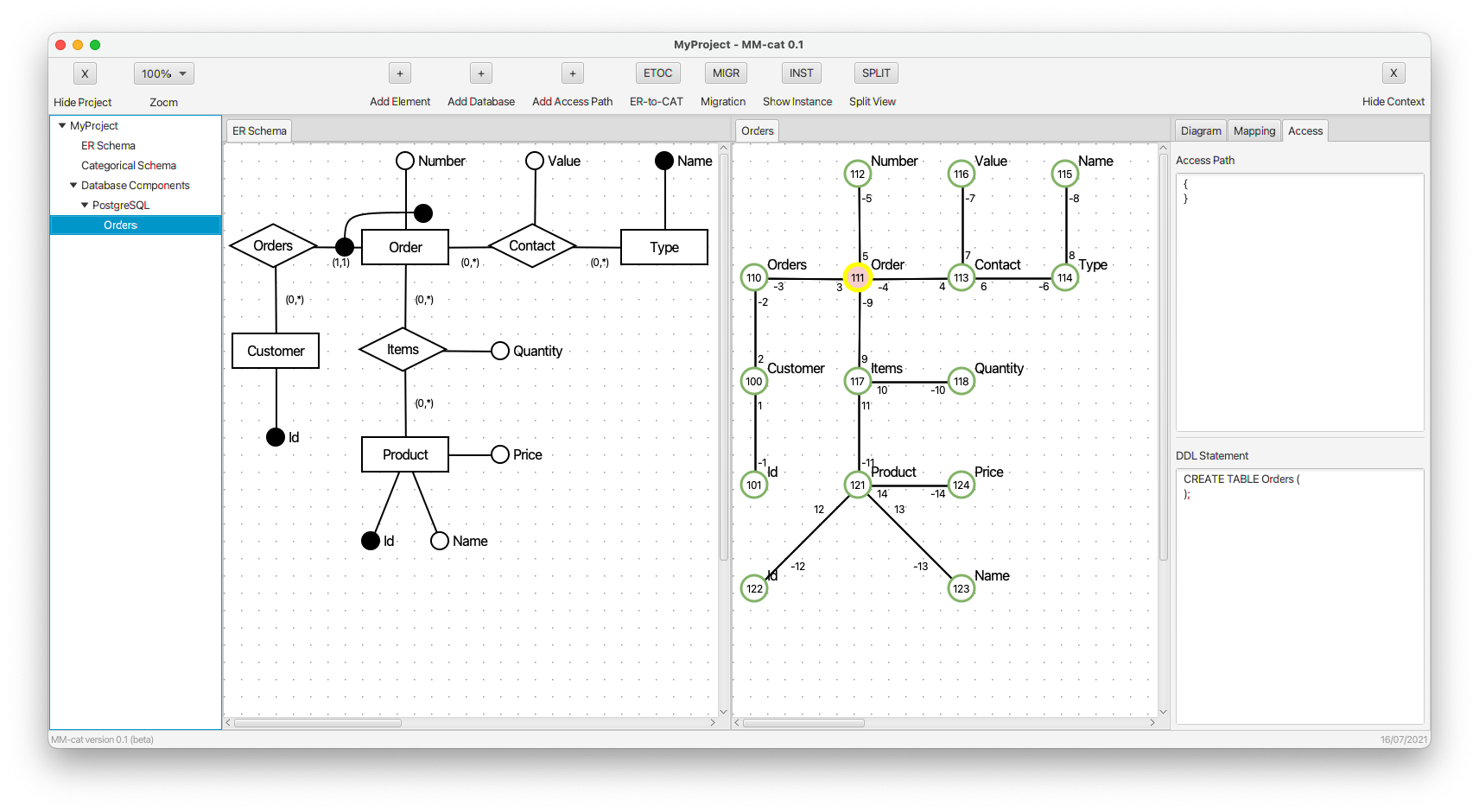
Relational model with multi-model extension (PostgreSQL):
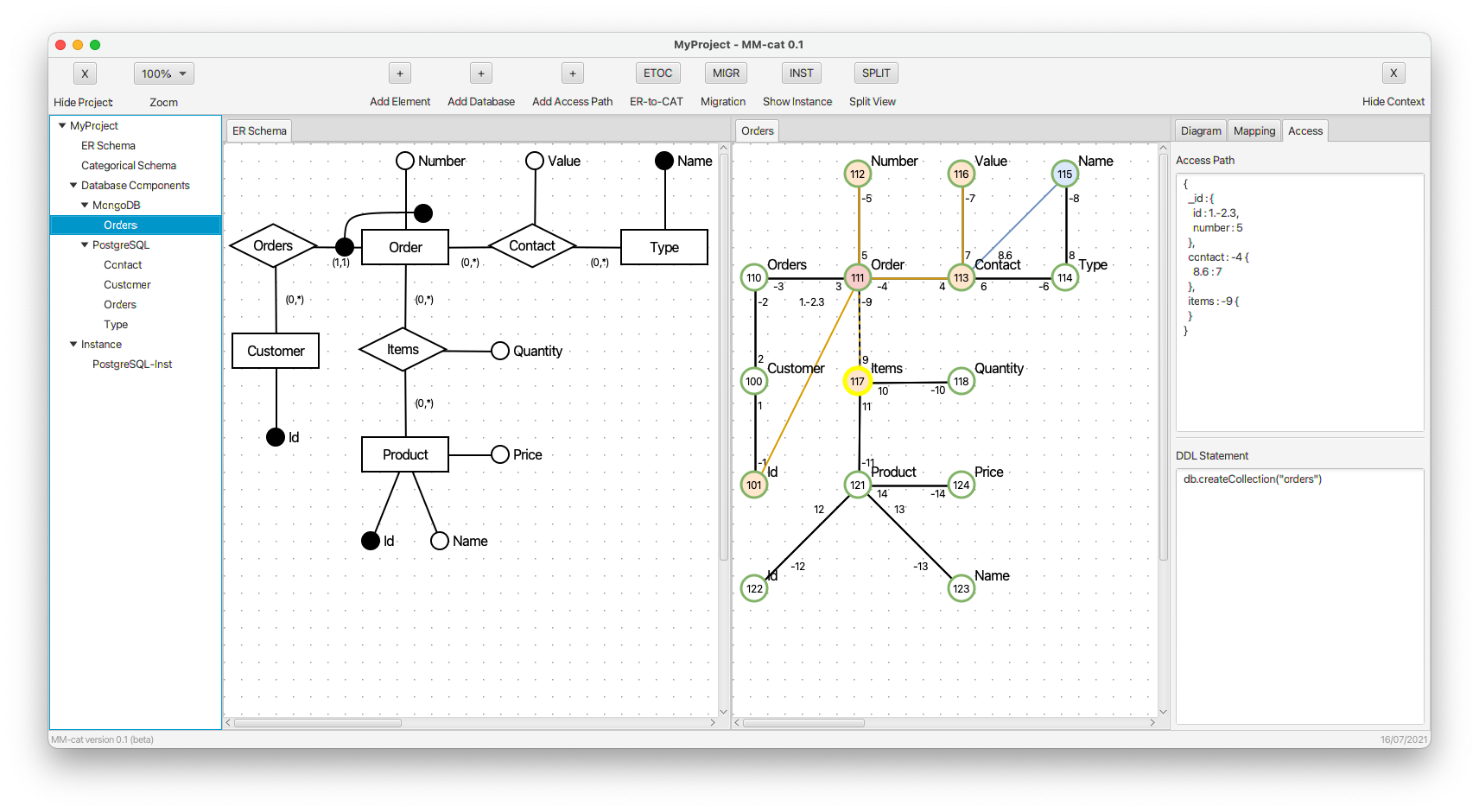
- The root object of kind (table) Orders is selected.
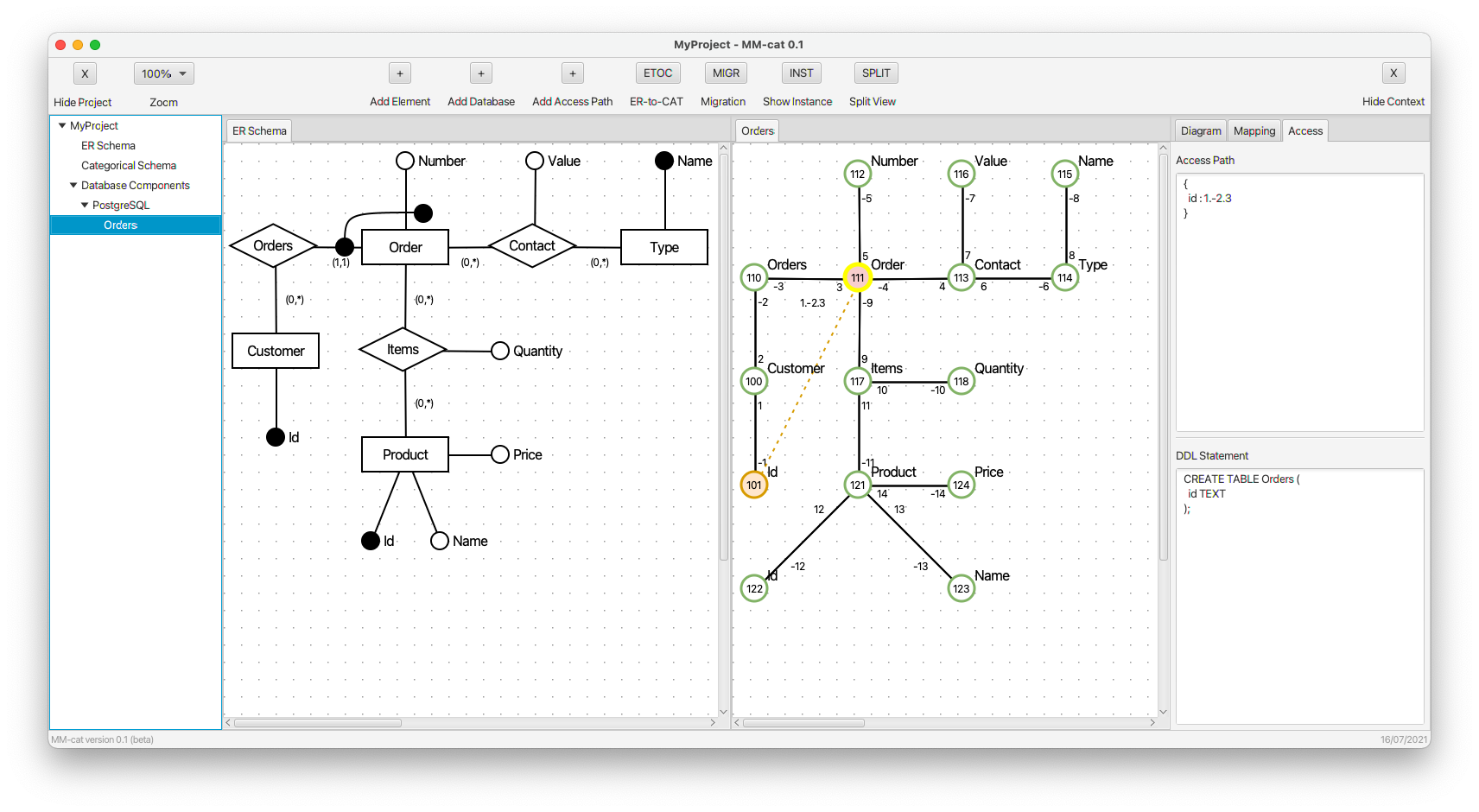
- Property id of a customer is inlined to kind (table) Orders via a path of length 4. Particular edges of the path are defined in the access path (see the panel on the right) using the concatenation of their simple signatures. The new composite morphism is denoted using the orange edge. It is dashed to indicate a warning that despite both the objects connected by the composite morphism have their identifier fully mapped, there are objects on the path of composition which do not. In the right panel, we can see not only the gradually changing access path, but also the changing CREATE command.
- Property number is added to kind (table) Orders. The identifier of orders is complete now, so the respective edge is now solid.
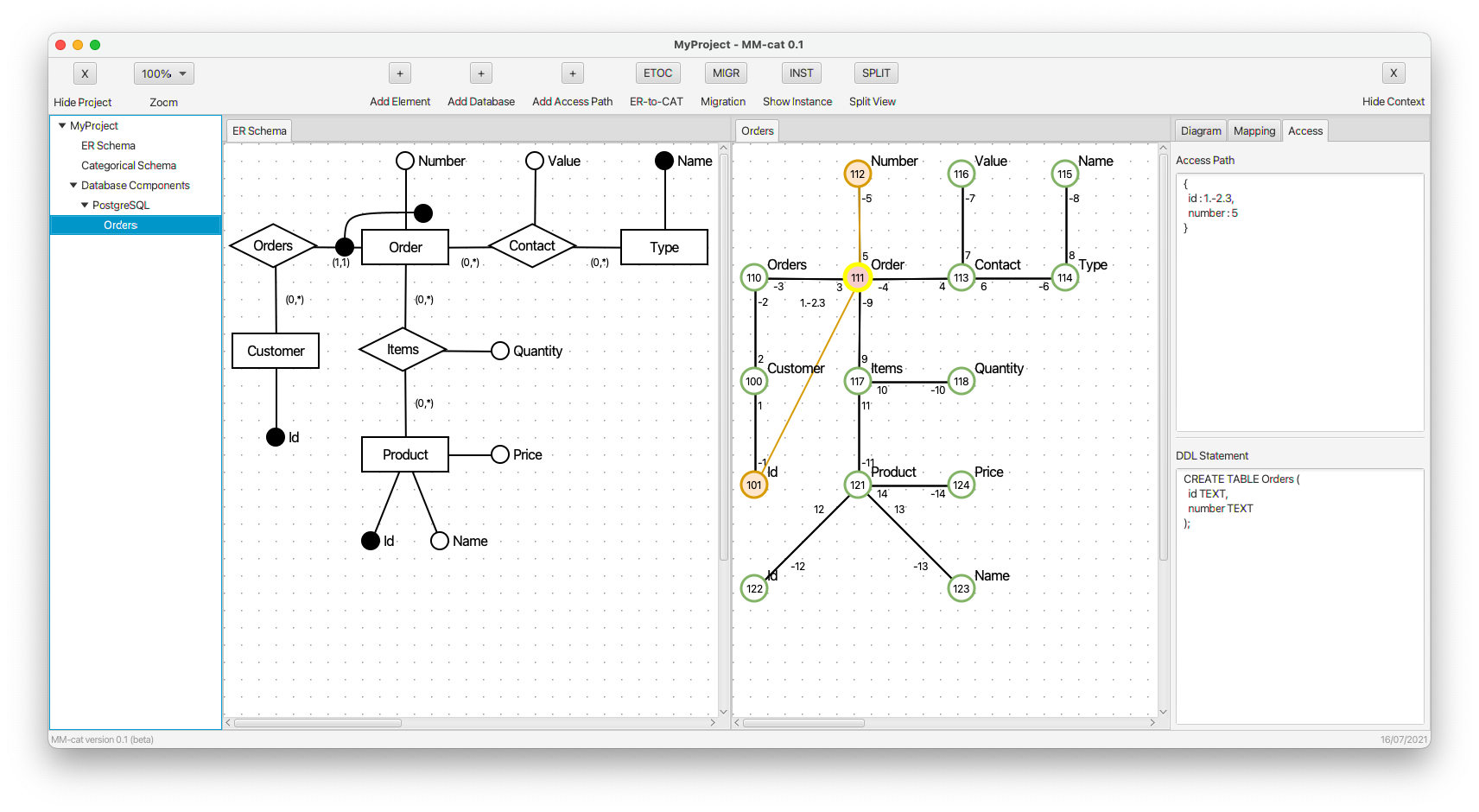
- Object Items is selected as another property of kind (table) Orders having a complex structure. In the case of PostgreSQL, it means that we combine the relational model with the document model (represented using data type JSONB) and, at the same time, a schema-full approach with a schema-less approach.
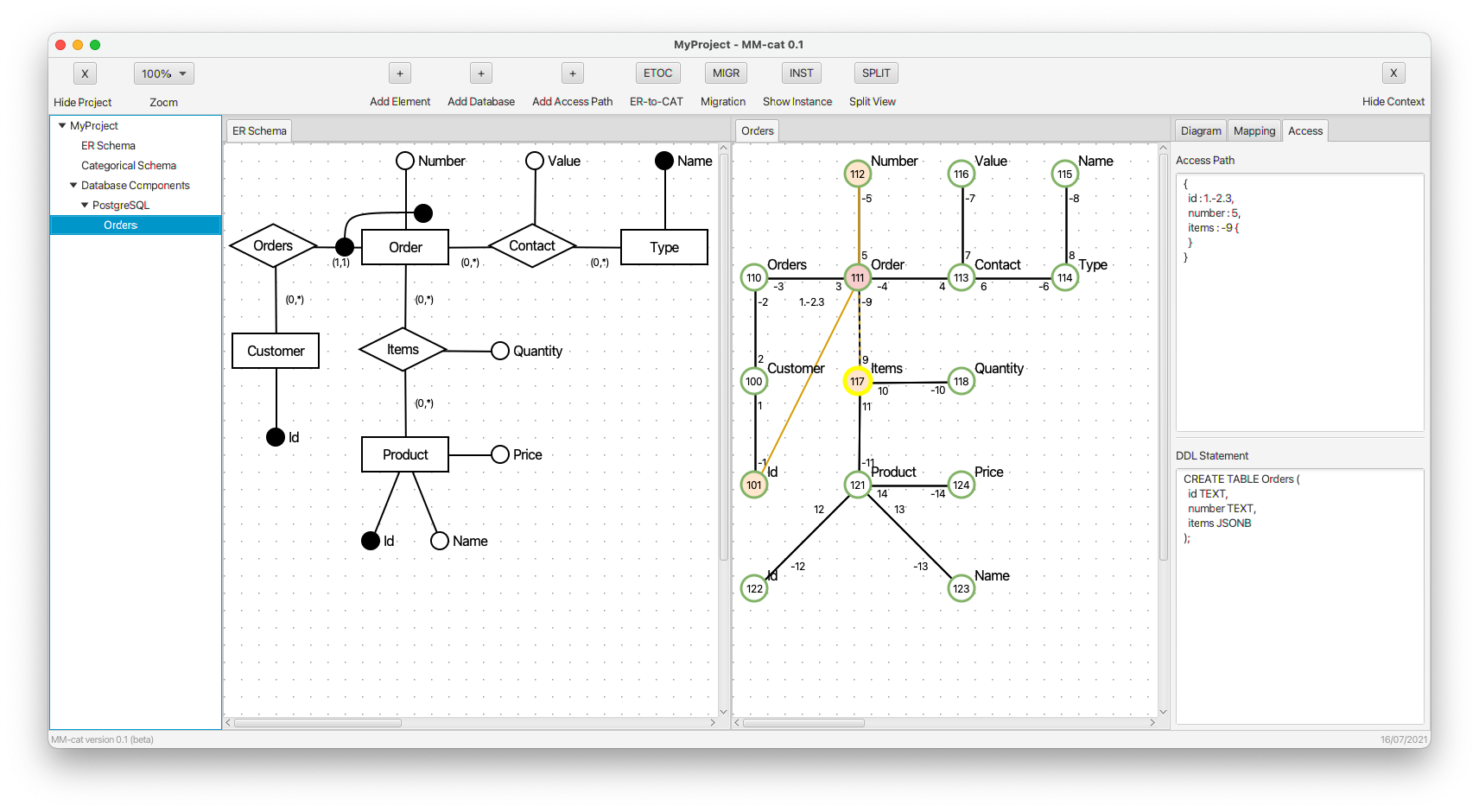
- Property quantity is added to property items. As we can see, the CREATE command remains unchanged, since the new property is a part of the schema-less document model. However, the access path is respectively extended.
- The whole complex property items is finished. The CREATE command remains unchanged, the access path is modified respectively.
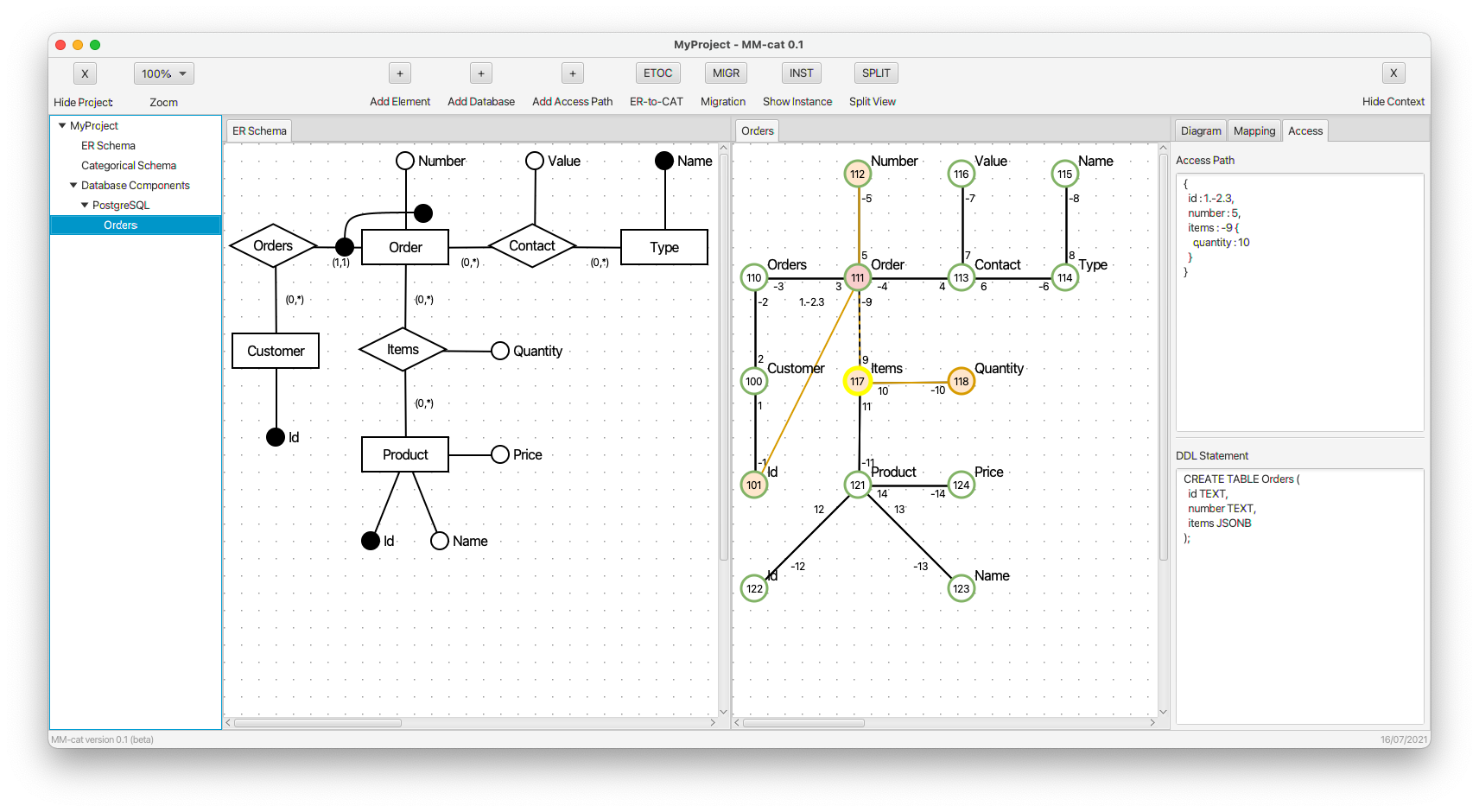
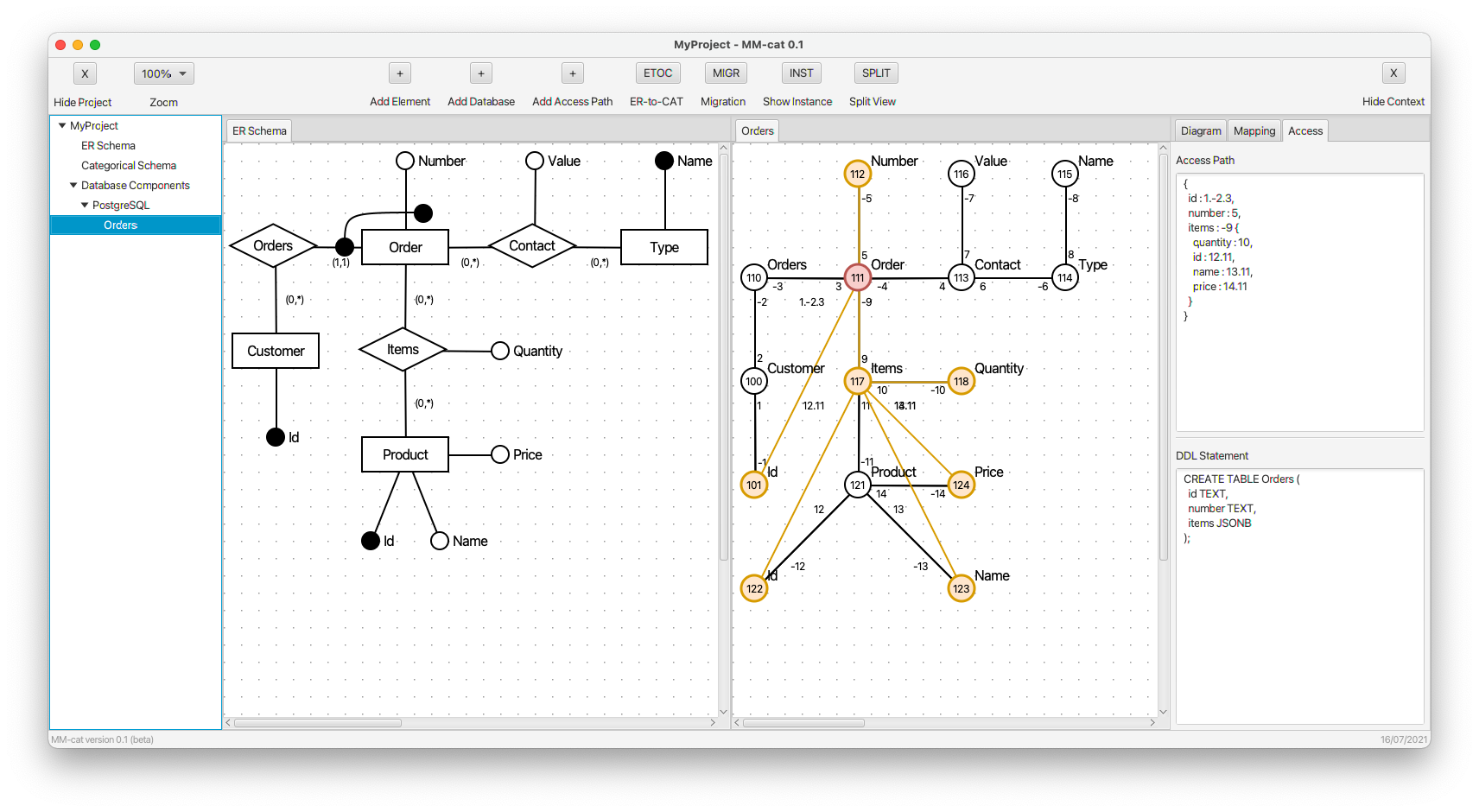
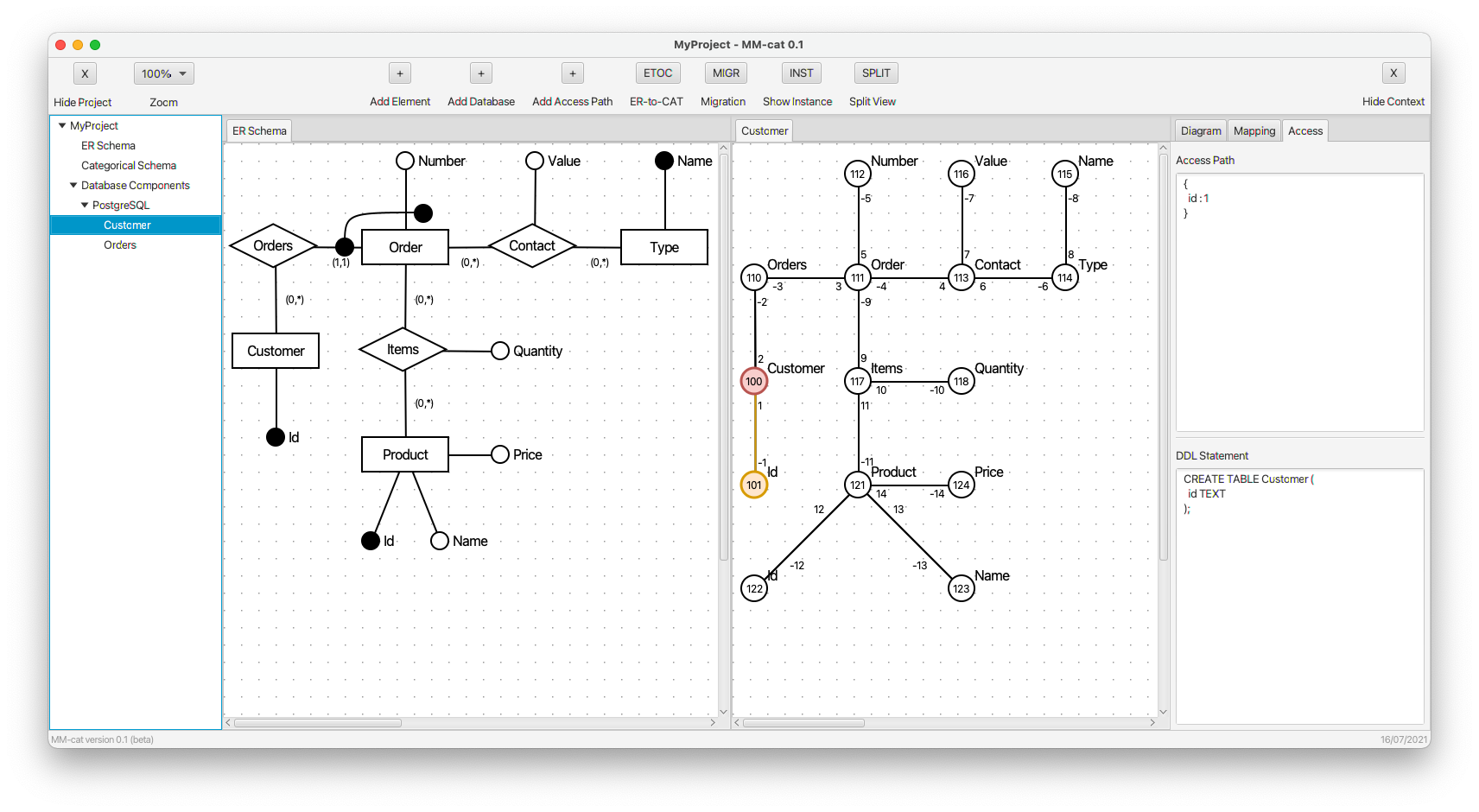
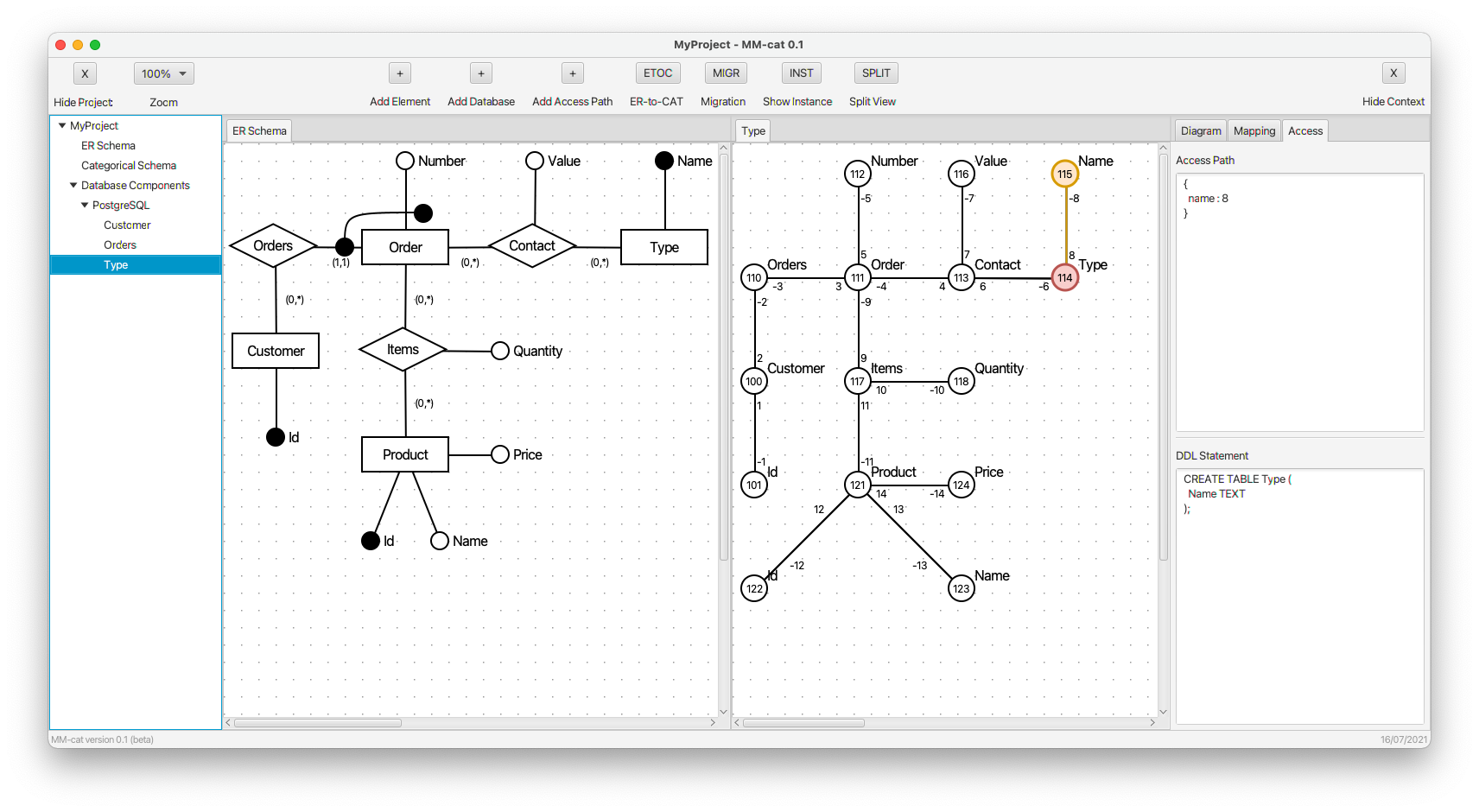
- For the sake of completeness of the mapping for further demonstration, simple kinds (tables) Customer and Type are mapped, too.
- For the sake of completeness of the mapping for further demonstration, simple kinds (tables) Customer and Type are mapped, too.
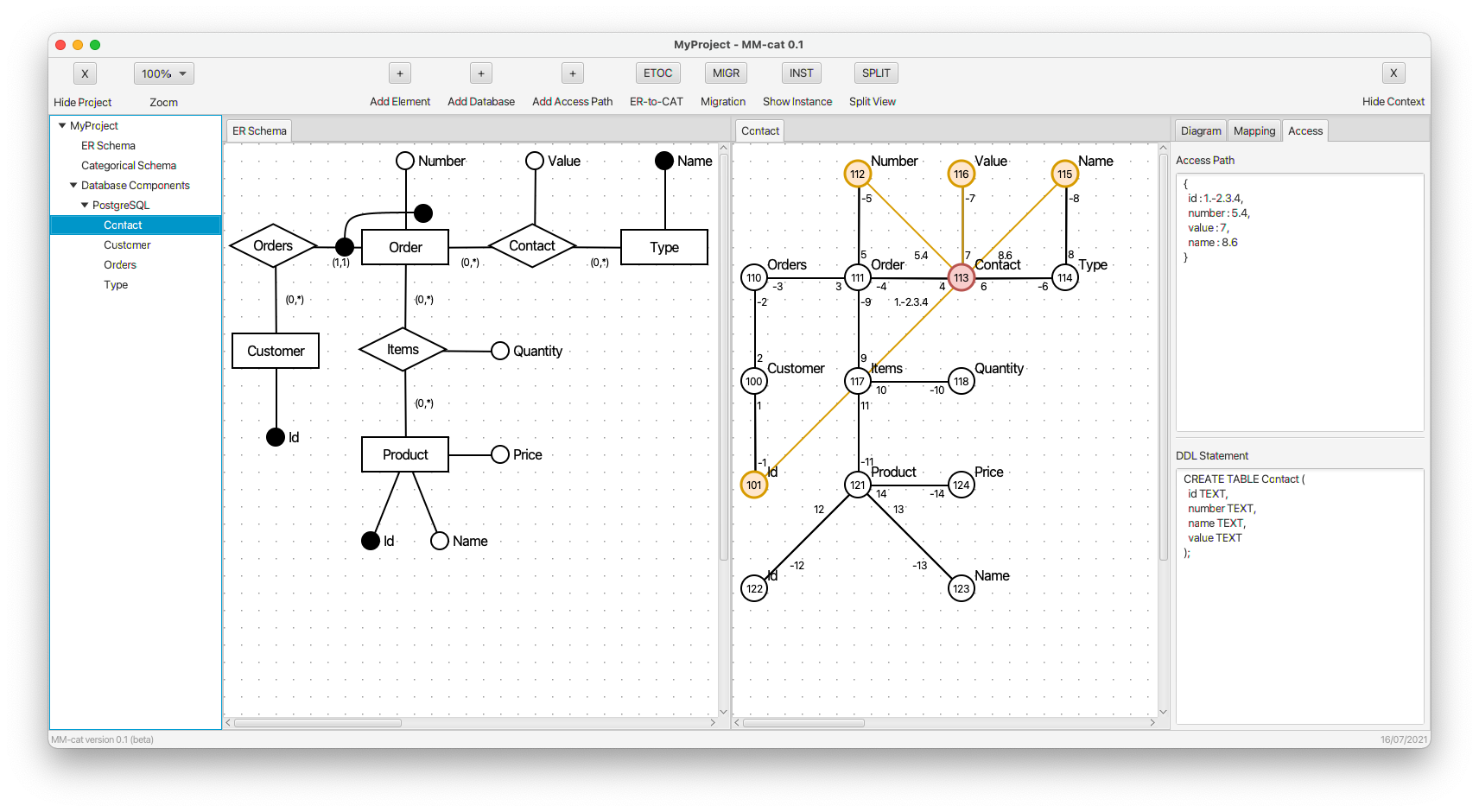
- Kind (table) Contact representing a relationship between kinds (tables) Type and Orders is mapped.
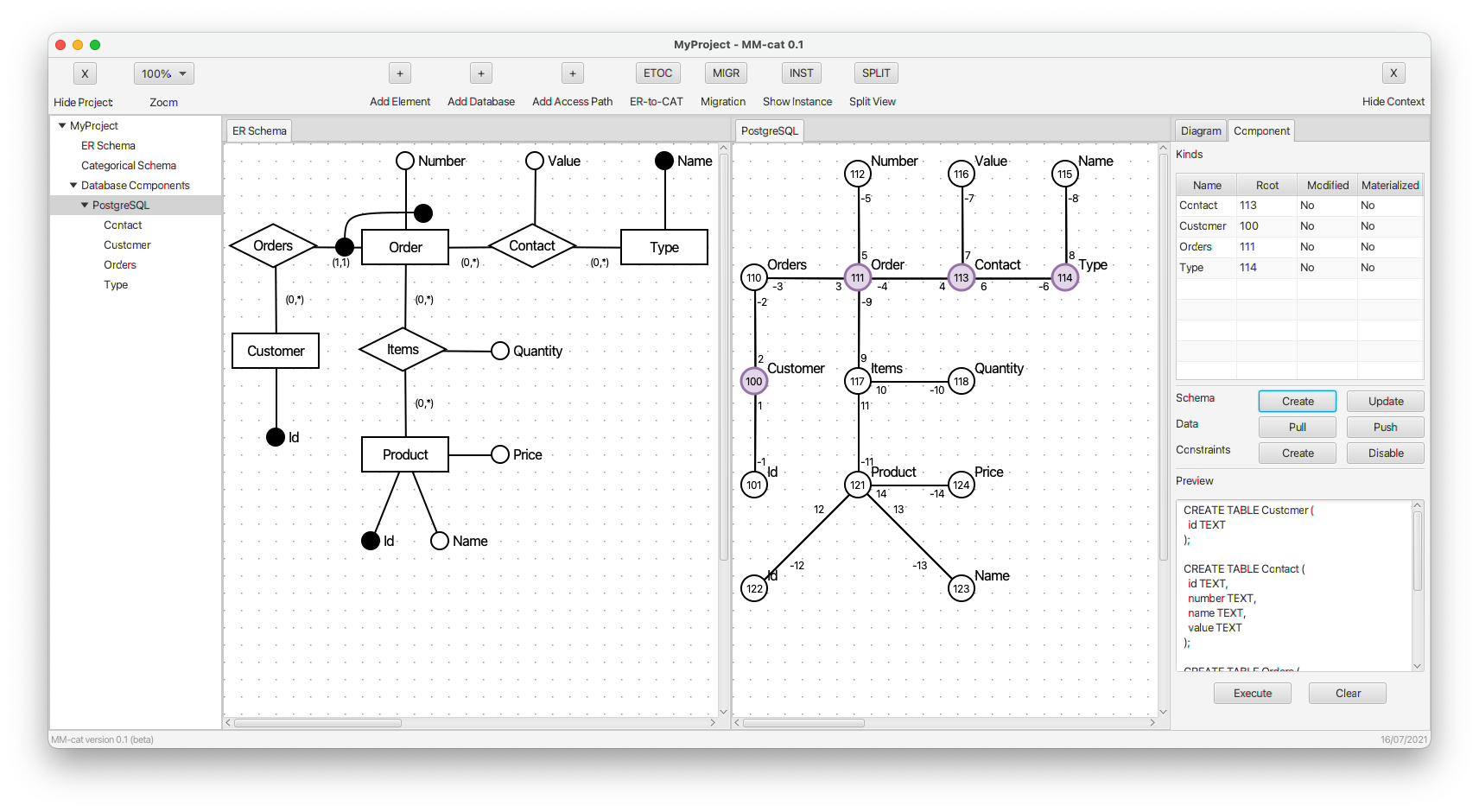
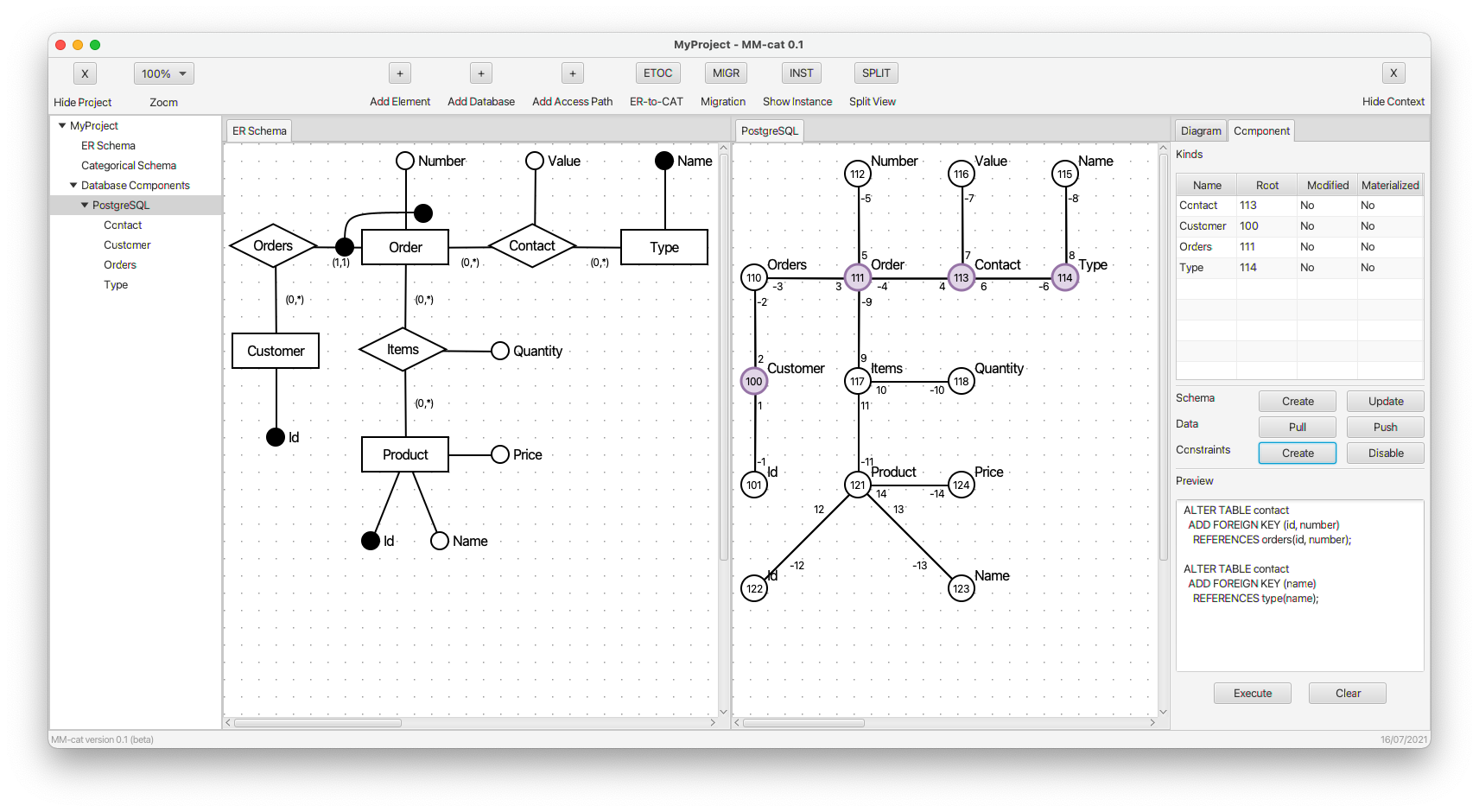
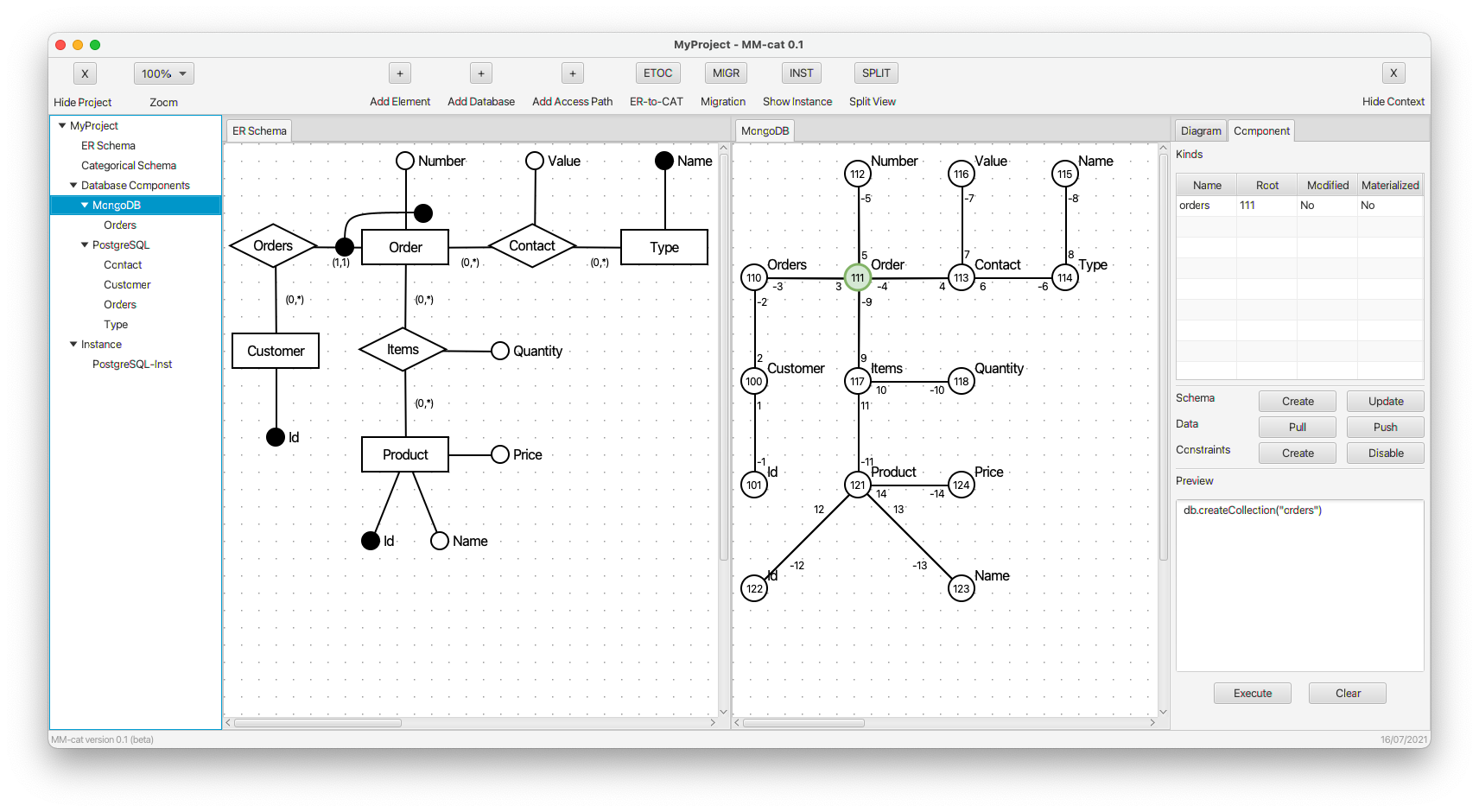
- An overview of all the created kinds (tables) is visualized. We can see four root objects of four kinds (Orders, Contact, Customer, Type). In the right panel, there are four respective CREATE commands. In the table above them we can see their list involving user defined names, references to root objects, and current status.
- The commands for addition of integrity constraints are generated and applied in PostgreSQL.
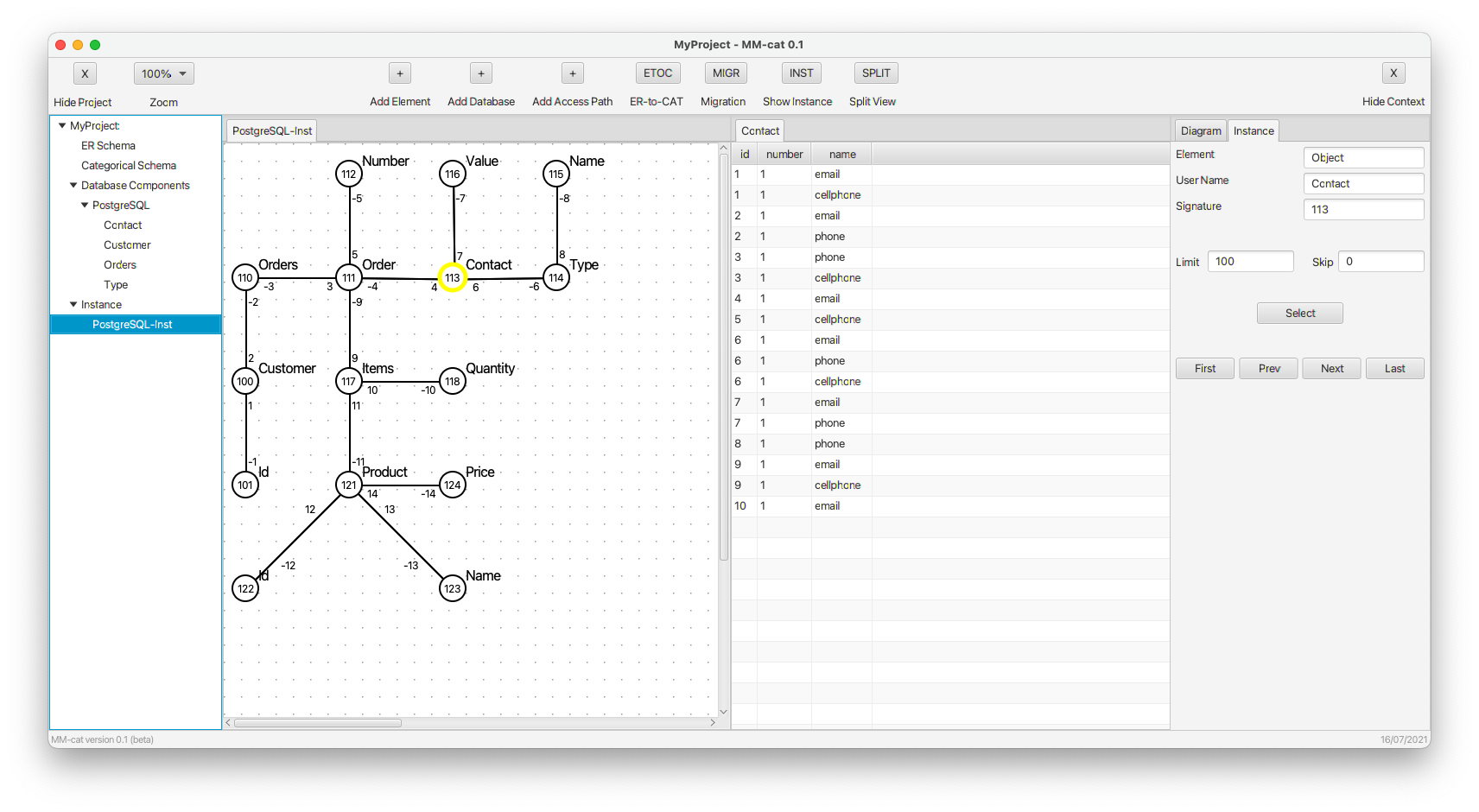
- The stored data are transformed to the respective instance category. For now, we use it for listing the content of the data structures (namely $superid$s of instances of the selected object) in the underlying DBMSs, i.e., we can perform only simple SELECT commands in order to check the status of the database. However, MM-cat is prepared for extensions towards robust querying over the categorical representation of the data. We can extract not only local instance categories for particular kinds of DBMSs, but also the global instance category involving all the multi-model data ready for cross-model querying and respective optimizations.
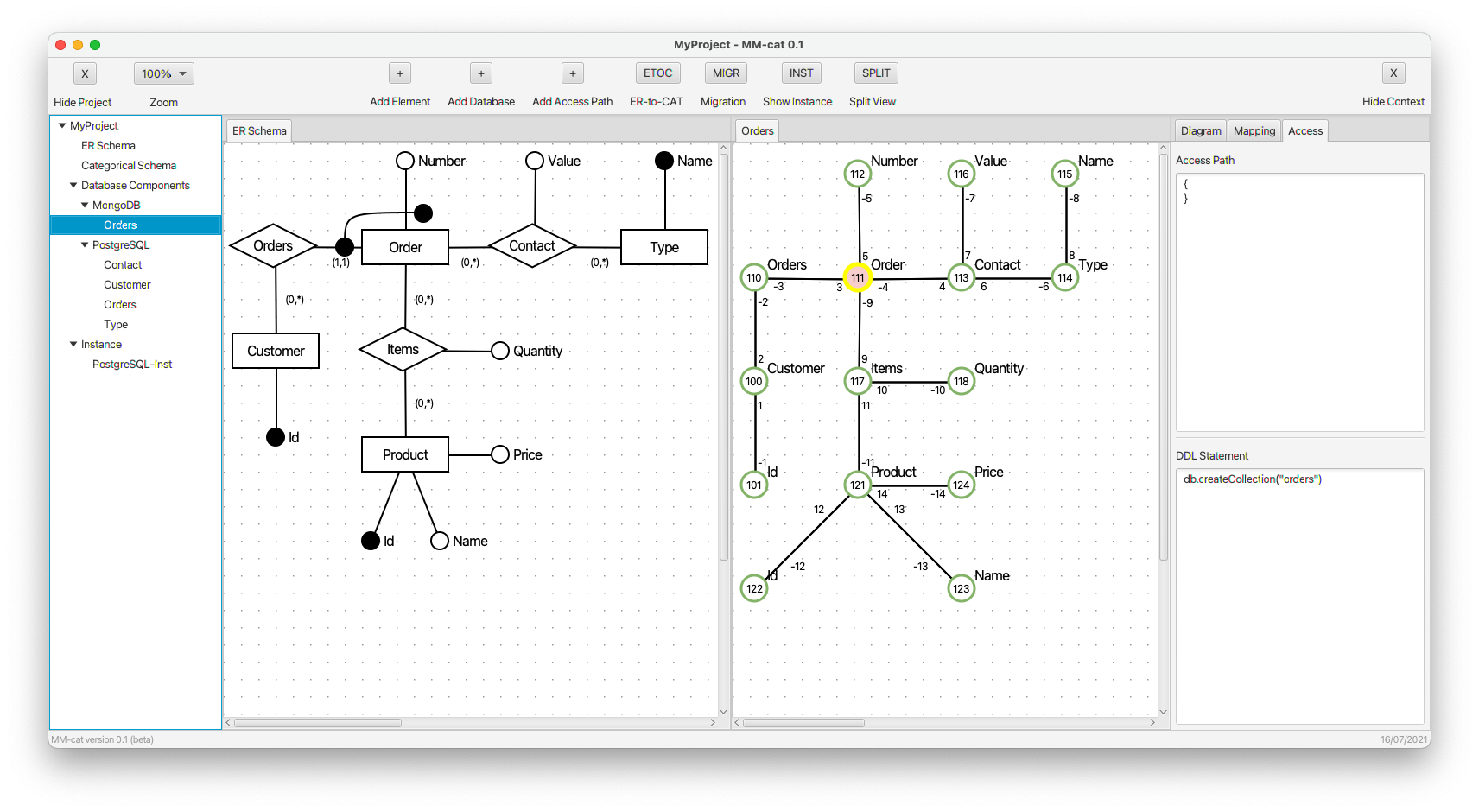
Document model (MongoDB) and demonstration of data migration:
- We again start to define the structure of kind orders, but this time as a document collection for MongoDB. It is a preparation for demonstration of data migration between PostgreSQL and MongoDB.
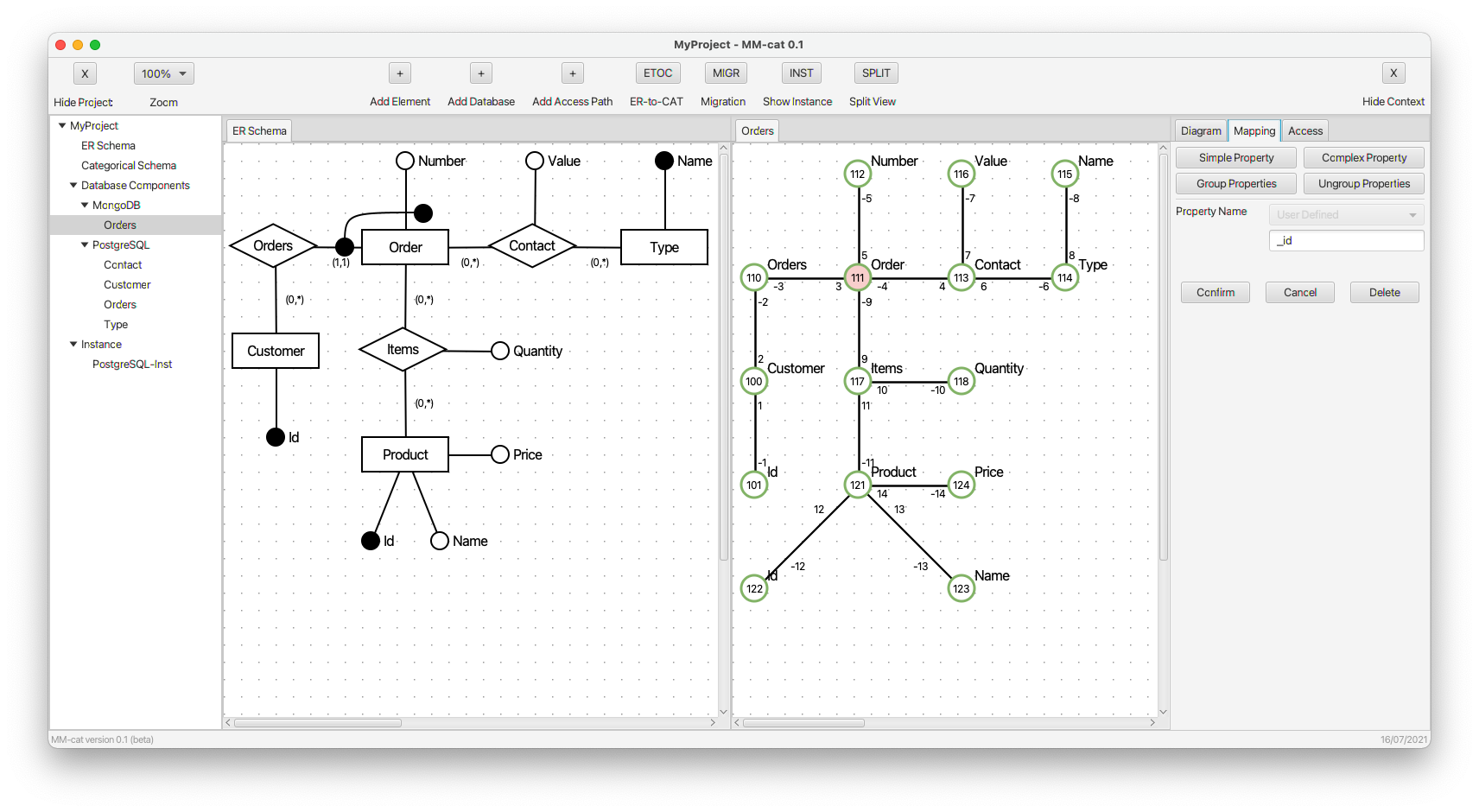
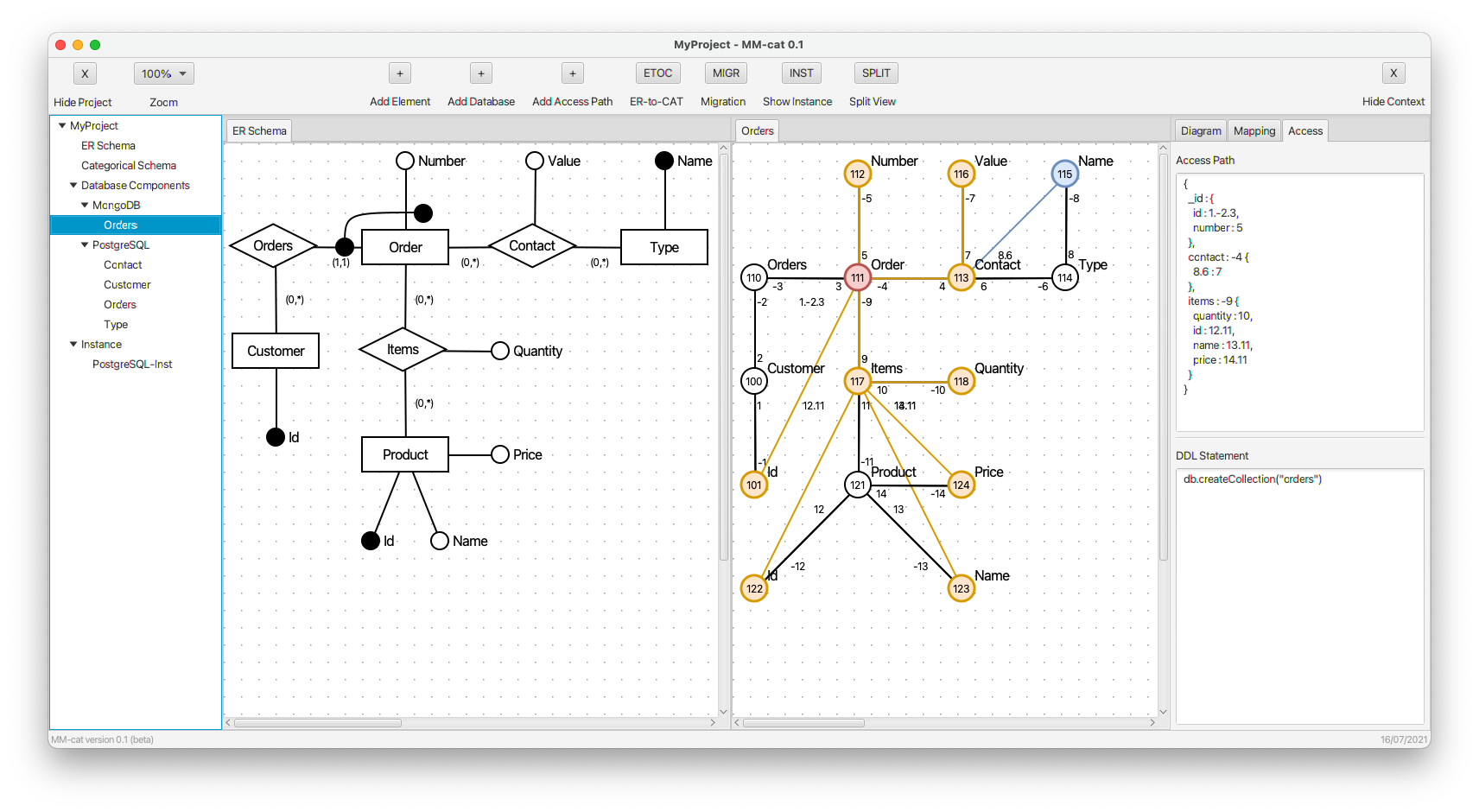
- An auxiliary property _id is created in order to group selected properties.
- Property id is inlined to auxiliary property _id. The new edge representing the composite morphism is dotted. This time, it represents an error, because one of the objects connected by the composite morphism does not have its identifier mapped completely.
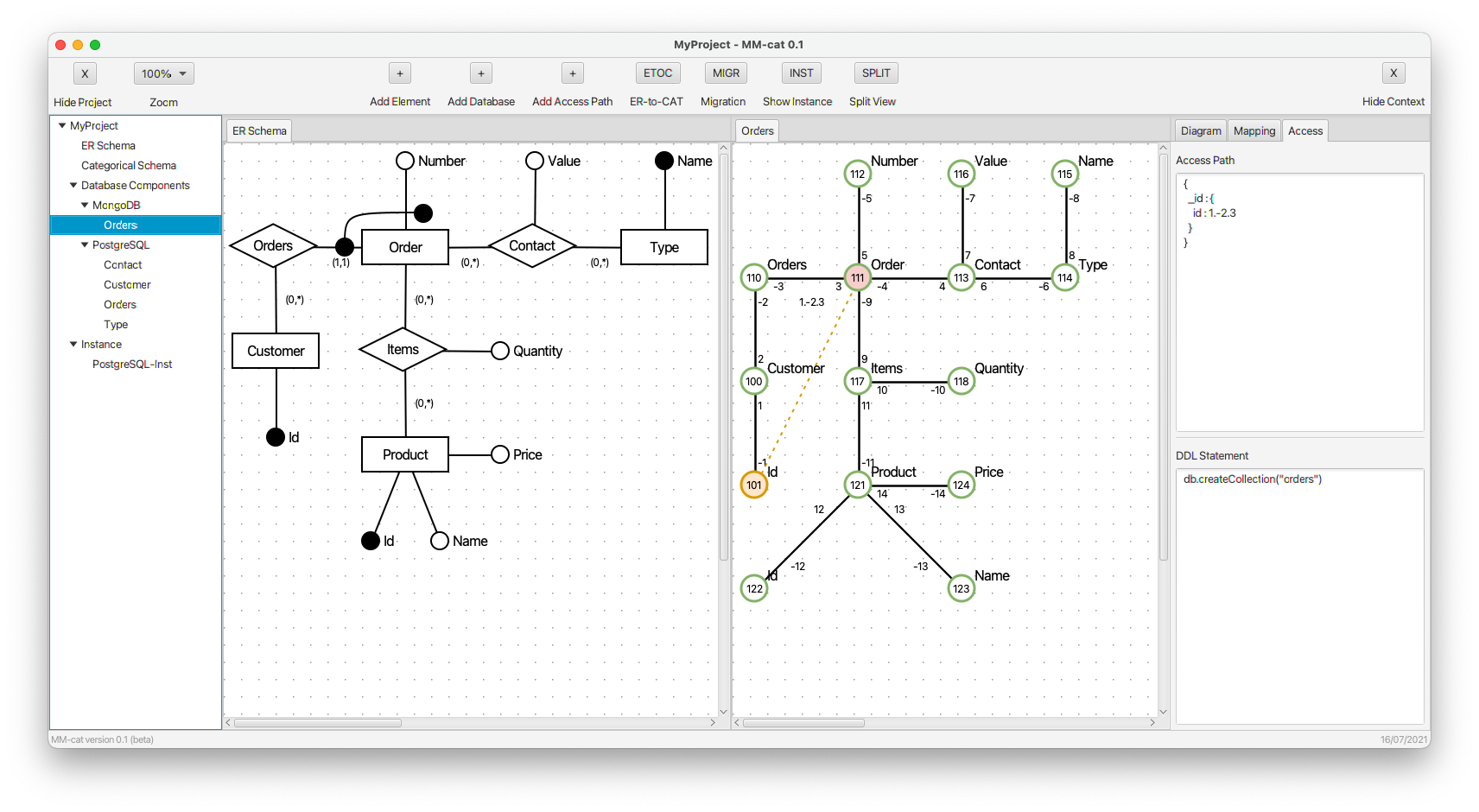
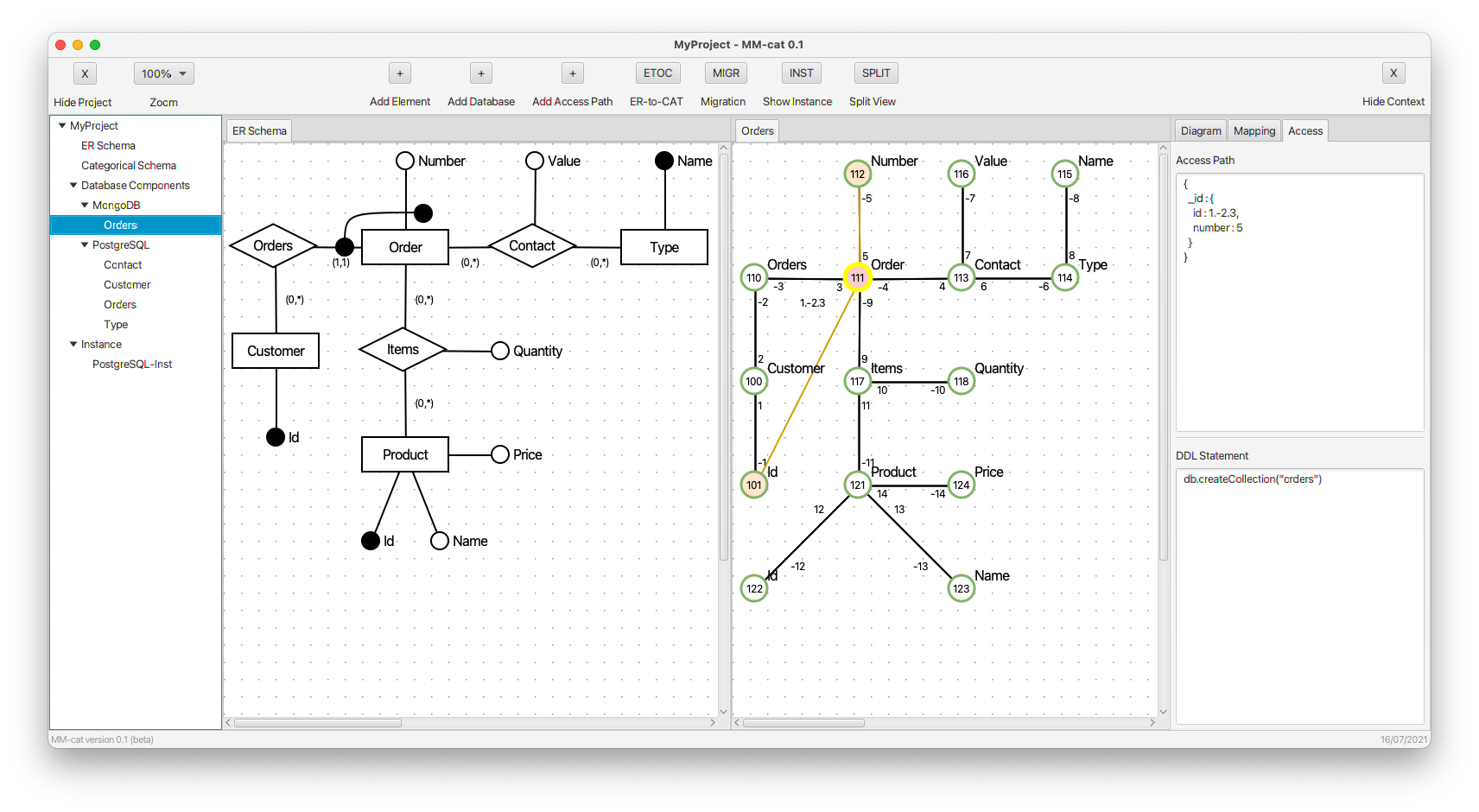
- When we also add property number to auxiliary property _id, both the new edges are solid, because the identifier is complete.
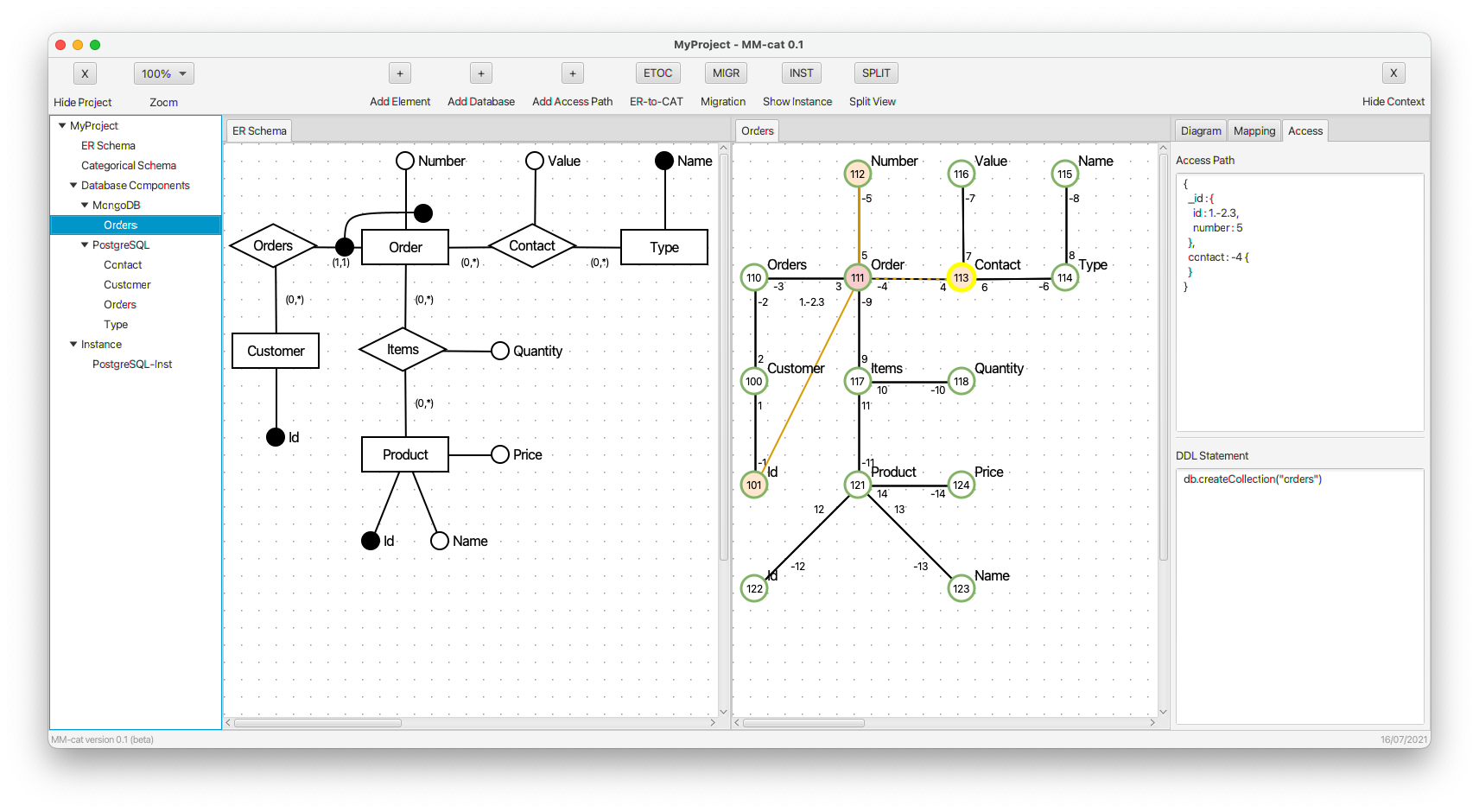
- We create a more complex structure by adding property contact.
- We define a property with dynamically derived names taken from object Name. (Its values are taken from object Value.) The respective new composite morphism specifying the dynamically derived name is blue.
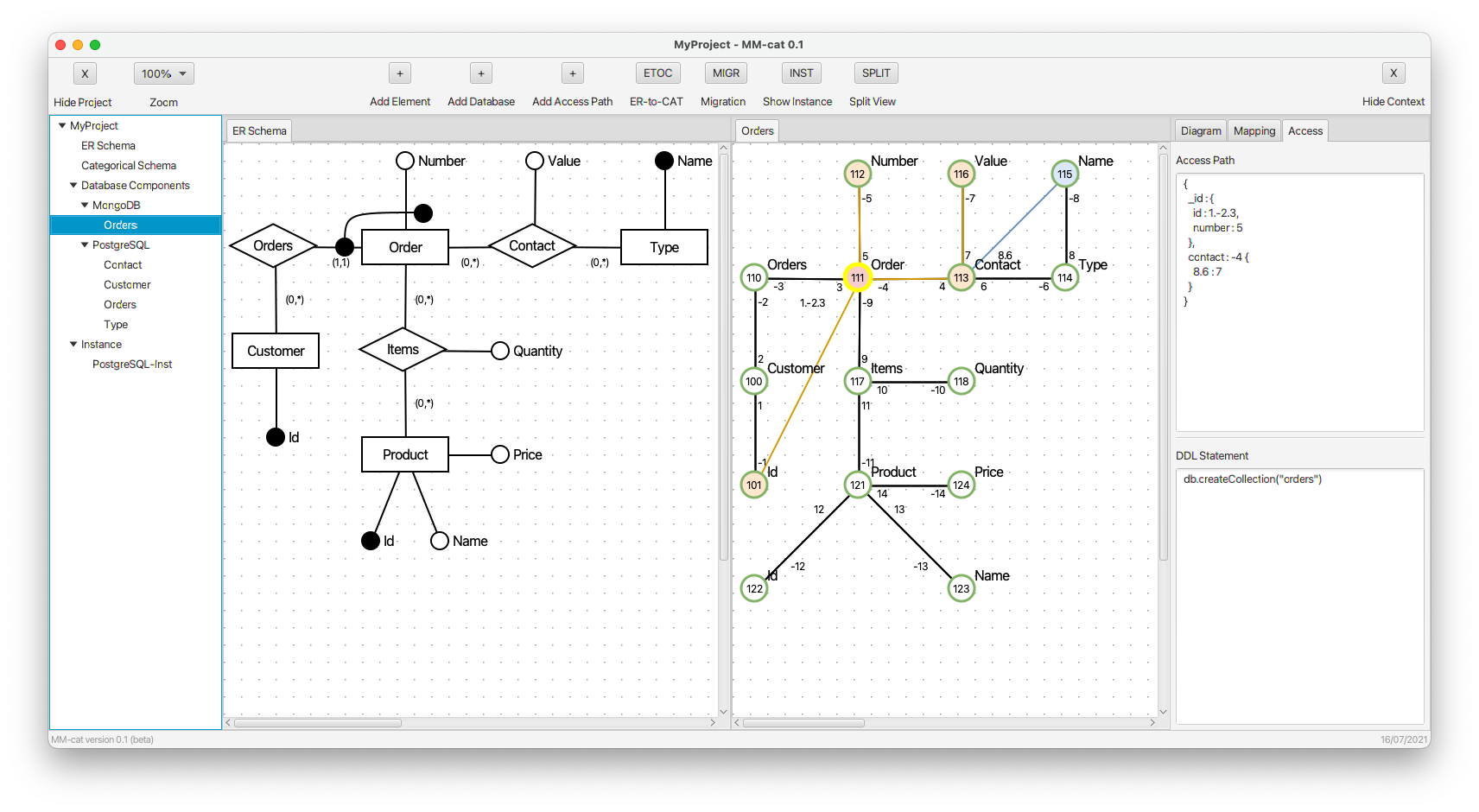
- Again, we specify the structure of complex property items.
- An overview of all the created kinds is visualized. Since MongoDB is schema-less, the commands for the definition of structures only cover creation of document collections, not their structure.
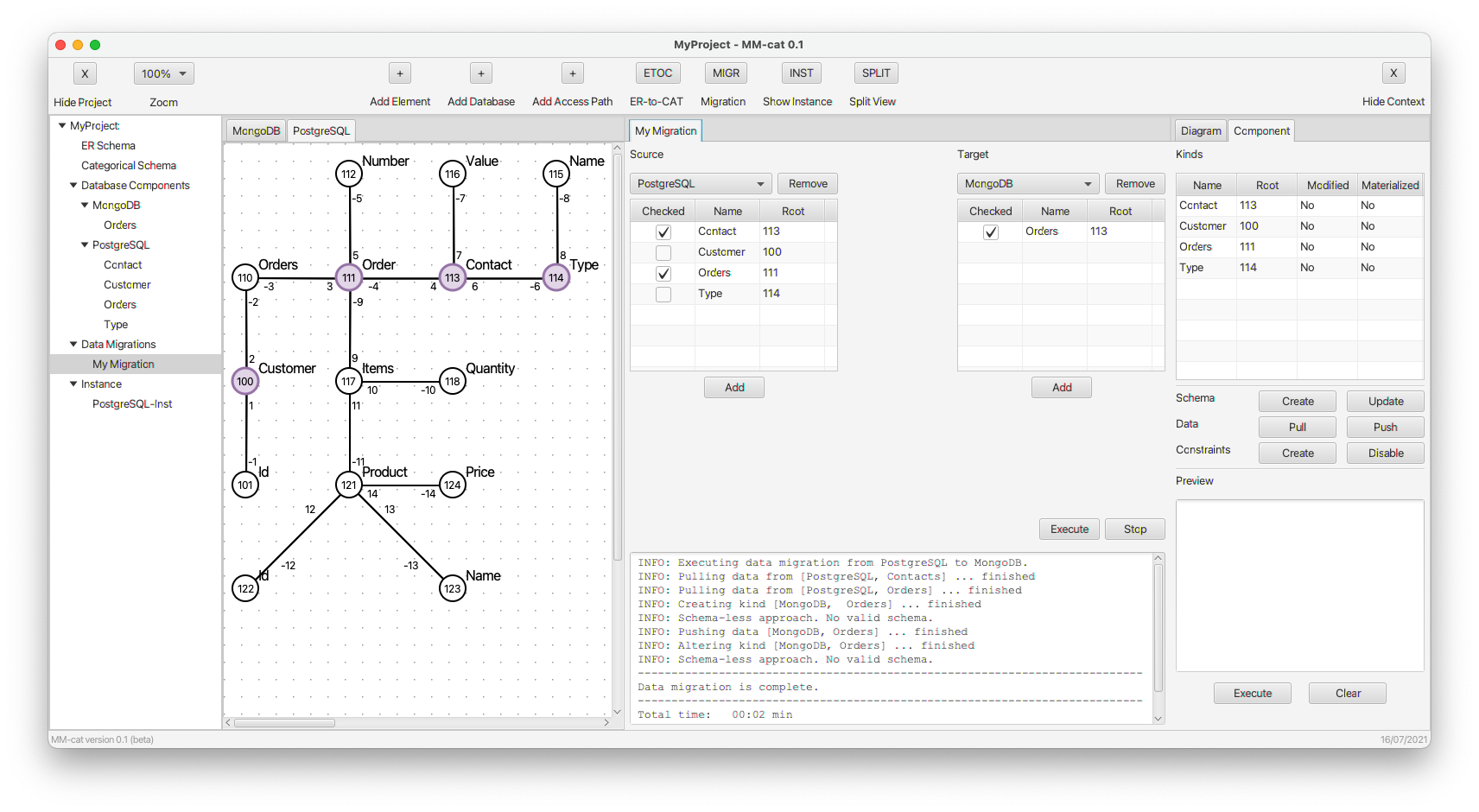
- Having the mapping of a part of the schema category to both MongoDB and PostgreSQL, we run the respective migration.
- Finally, we check that the data were successfully migrated to MongoDB. If we now delete the part mapped in the document model of PostgreSQL, we get a polystore-like situation of the original multi-model mapping in PostgreSQL -- the document part is now mapped to a separate DBMS (MongoDB).
Publications
- Pavel Koupil, and Irena Holubová. 2022. Unifying Categorical Representation of Multi-Model Data. In SAC ’22: 37th ACM/SIGAPP Symposium On Applied Computing (SAC 2022), Brno, Czech Republic, April 2022. ACM, 2022 (accepted) DOI: 10.1145/3477314.3507690
- Pavel Koupil, Martin Svoboda, and Irena Holubová. 2021. MM-cat: A Tool for Modeling and Transformation of Multi-Model Data using Category Theory. Proceedings of the ACM/IEEE 24th International Conference on Model Driven Engineering Languages and Systems (MODELS 2021), Fukuoka, Japan, October 2021. IEEE, 2021. DOI: 10.1109/MODELS-C53483.2021.00098
- Irena Holubová, Pavel Čontoš, and Martin Svoboda. 2021. Multi-Model Data Modeling and Representation: State of the Art and Research Challenges. In 25th International Database Engineering & Applications Symposium (IDEAS 2021). Association for Computing Machinery, New York, NY, USA, 242–251. DOI: 10.1145/3472163.3472267
- Irena Holubová, Pavel Čontoš, and Martin Svoboda. 2021. Categorical Management of Multi-Model Data. In 25th International Database Engineering & Applications Symposium (IDEAS 2021). Association for Computing Machinery, New York, NY, USA, 134–140. DOI: 10.1145/3472163.3472166
- Martin Svoboda, Pavel Čontoš, and Irena Holubová. 2021. Categorical Modeling of Multi-Model Data: One Model to Rule Them All. In International Conference on Model and Data Engineering (MEDI 2021), Tallinn, Estonia, June 2021. Lecture Notes in Computer Science, volume 12732, Springer, Cham, 2021. p. 190-198. ISBN 978-3-030-78427-0. DOI: 10.1007/978-3-030-78428-7_15